
Программа для структурирования информации: В чем хранить записи, информацию
В чем хранить записи, информацию
В дополнение к статьям «Как успевать больше» и «Как внедрять в жизнь крупные изменения» я решила сделать еще одну статью, где подробнее раскрываю инструмент, без которого я не могу представить свой день. Который позволяет мне и успевать больше, и планировать в нем большее.
У меня десятки, а иногда и сотня контактов в день с людьми. Я выдаю массу информации, к которой я должна иметь быстрый доступ. В голову постоянно приходят какие-то идеи или появляются дела, которые нужно сделать. И так далее.
Насколько хаотично проходил бы мой день, если бы у меня не было единого места, где я могу записывать:
— список что сделать сегодня
— отдельно список мелких дел для буферных дней
— фрирайтинг, любые мысли чтобы разгрузить мозг, какие-то проработки и упражнения
— всевозможные дневники и отчеты — мои личные, стодневки и разные другие
— большие цели и все что приходит мне в голову из разряда «а хорошо бы»
— крупные цели и все, что их касается
— любые списки типа сделать, купить
— какая-то полезная информация которую надо держать в быстром доступе, в одном месте, где легко найти — каких посылок жду и их коды отслеживания, мои кошельки и платежные данные, кто в подопечных по благотворительности, списки по вьетнаму — людей, магазинов или клиник, которые могут быть полезны,
— веду список финансов — сколько приходит ежедневно, ежемесячно и куда мне сколько нужно в ближайшее время
— списки что сделать по отдельным проектам, куда я могу все записывать, чтобы не забыть
— полезные ссылки — на мои главные статьи, мои бесплатные курсы, реферальные ссылки и так далее
— данные по моим бонусам по хрумеру, обновление топ базы и пр.
— группы, которые хочу послушать и фильмы посмотреть, книги почитать
— что я хочу скачать-докачать — список ссылок по темам
— что мне понадобится в поездке в следующую страну
— список ресурсов по спорту, запись пищевого дневника или программы тренировок
— какие-то данные, к которым могу захотеть вернуться позже — про ноотропы или анскулинг или хорошие советы, чем лечить ребенка в том или ином случае и т.д.
— мои тренинги, которые сейчас прохожу — информация, ссылки в кабинет, задания, выполненные мной задания
— короткие посты в мои соцсети, которые часто использую или надо будет использовать часто в ближайшее время и надо не забыть
— идеи для постов в мой SEO-блог
«Как сохранить себя во время перегруза». Научитесь за 3 дня существенно снижать напряжение и давление на себя при перегрузах на работе и дома. Обретите контроль над своим состоянием. Мои лучшие 10+ секретов продуктивности и стабилизации своего состояния, о которых не говорят.

и всякую другую информацию, которая может мне понадобиться в любой момент. Про которую я должна знать, где ее искать. Ну и вообще, иметь очень удобный инструмент, где можно записать что угодно.
Эта же программа может быть очень удобной для ведения SEO-проектов, сохранения информации по изменениям и всевозможных идеях, что сделать с сайтом, ссылок на полезные материалы и так далее.
О том, как я работаю сейчас со списками, как структурирую информацию, делю свои дела и другие интересные организационные лайфхаки я подробно описала в статье «Эффективная работа со списками и жизнью. Успевать все самое важное».
Существуют самые разные органайзеры, так называемые «менеджеры персональной информации».
Много лет назад я пересмотрела все, какие смогла найти. Evernote тоже смотрела, но он мне совсем не приглянулся ни интерфейсом, ни отсутствием древовидной структуры — от этого у меня в записях в Evernote довольно быстро начался полный бардак.
В итоге я остановилась на двух примерно равнозначных — EssentialPIM и AllMyNotes Organizer.
Что мне было нужно от органайзера:
— не ограниченная по уровням вложенности древовидная структура
— возможность делать разные цвета, жирность у названий категорий и файлов в дереве, иконки и приоритетность рядом с ними — т.е. чтобы самые частые разделы я могла выделять и находила визуально моментально.
— поиск по всем заметкам или только выбранным
— возможность внутри заметок все выделять как в MS Word, легко вставлять изображения и так далее.
Оба всем этим требовниям удовлетворяют. Обе программы имеют в том числе и русский интерфейс.
У меня есть несколько файлов — отдельно самый главный мой файл, открытый весь день, он же еще и под паролем. И отдельно несколько других, которые я открываю гораздо реже.
Отдельно — файлы по языкам (испанский, индонейзийский). Отдельно — по конспектам Эволюции, Палиенко и пр. кто мне особенно интересен. Отдельно — по некоторым тренингам с особо глубокой проработкой (хотя чаще всего эта информация идет в основном файле). И отдельным файлом там же хранится система некоторых коспектов, лучших идей, заметок, цитат, кусков статей и пр. по SEO, интернет-маркетингу (пока ищу более совершенную систему знаний).
кто мне особенно интересен. Отдельно — по некоторым тренингам с особо глубокой проработкой (хотя чаще всего эта информация идет в основном файле). И отдельным файлом там же хранится система некоторых коспектов, лучших идей, заметок, цитат, кусков статей и пр. по SEO, интернет-маркетингу (пока ищу более совершенную систему знаний).
Какие нюансы:
EssentialPIM более навороченный и симпатичный. У меня PRO версия (покупается один раз), но вроде и бесплатной достаточно. Но он тяжелее — если внутрь заметок вставлять много картинок и делать большое дерево, то он начнет тяжело ворочаться на компьютере, подвисать иногда. Язык на сайте сразу есть русский, не помню, как он устанавливается, кажется, сразу выбор при установке.
AllMyNotes Organizer полегче, но чуть попроще интерфейсом. Одно время я с удовольствием работала в нем, но потом пару раз он сглючил и исчезли мои последние сохраненные данные (возможно, потому что файлы сильно разрослись) — тогда я перешла обратно на EssentialPIM и просто стараюсь почаще убирать из основного файла старые и ненужные данные, облегчать его.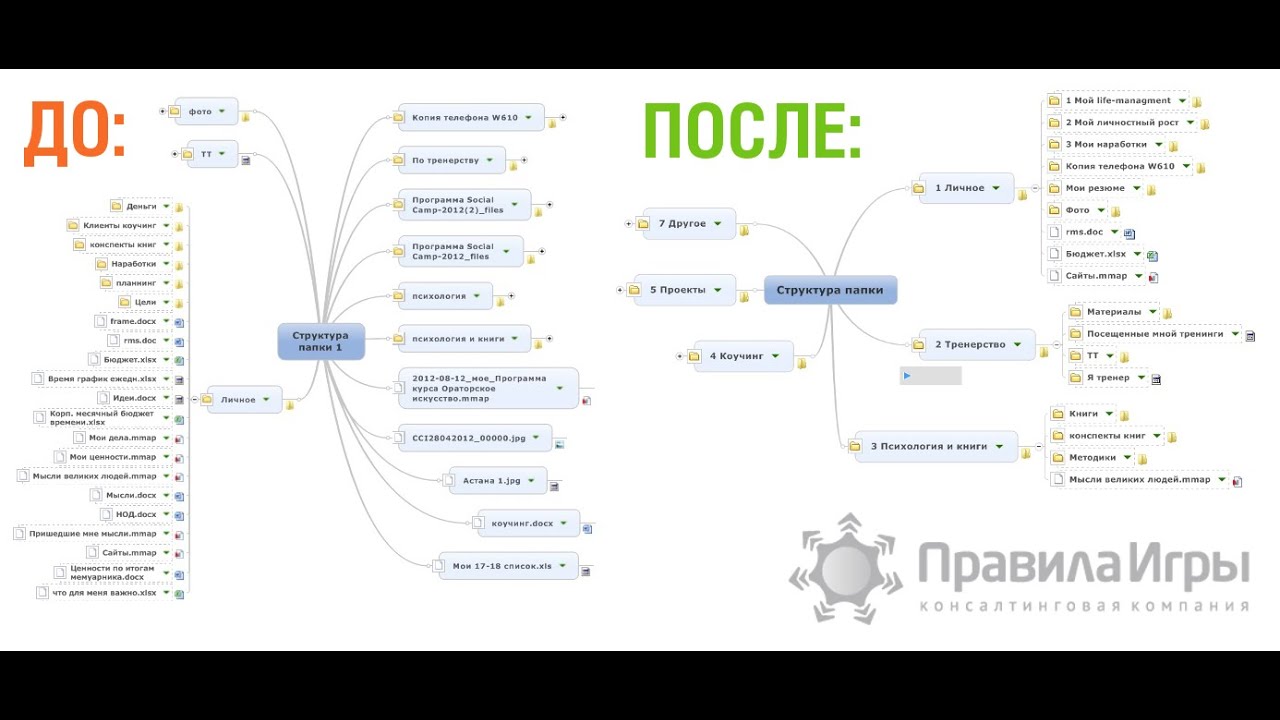 Не помню, как устанавливается русский язык, но в навигационном меню программы есть раздел «Инструменты» — там «Настройки» — там в окошке — «Язык» (ну т.е. возможно, при первичной установке все это по английски и надо сменить на русский, не помню).
Не помню, как устанавливается русский язык, но в навигационном меню программы есть раздел «Инструменты» — там «Настройки» — там в окошке — «Язык» (ну т.е. возможно, при первичной установке все это по английски и надо сменить на русский, не помню).
Не представляю, где и как еще можно хранить так же удобно все эти данные.
Интерфейс у обеих программ очень простой и интуитивный. Вот это только одна из моих раскрытых рабочих подкатегорий в EssentialPIM. Тут видно, что я могу делать разные цвета у заголовков заметок в дереве, разную жирность, разные иконки рядом, любой уровень вложенности.
Каждый уровень в дереве сам по себе тоже является заметкой, а не просто папкой.
Если у вас есть какие-то интересные мысли или наработки на эту тему, или вопросы — пишите!
Пара других инструментов или лайфхаков, без которых я тоже не представляю свой день в плане удобства работы за компьютером:
«Запинить все»
Программа для скриншотов
Все мои проекты, кроме этого SEO-блога:
ТОП База — база для полуавтоматической регистрации с Allsubmitter или для полностью ручного размещения — для самостоятельного бесплатного продвижения любого сайта, привлечения целевых посетителей на сайт, поднятия продаж, естественного разбавления ссылочного профиля. Базу собираю и обновляю 10 лет. Есть все виды сайтов, все тематики и регионы.
Базу собираю и обновляю 10 лет. Есть все виды сайтов, все тематики и регионы.
SEO-Topshop — SEO-софт со СКИДКАМИ, по выгодным условиям, новости SEO-сервисов, баз, руководств. Включая Xrumer по самым выгодным условиям и с бесплатным обучением, Zennoposter, Zebroid и разные другие.
Мои бесплатные комплексные курсы по SEO — 20 подробных уроков в формате PDF.
«Приближаясь..» — мой блог на тему саморазвития, психологии, отношений, личной эффективности
Мои группы по SEO в соцсетях — там ежедневно много полезного: Фейсбук, вКонтакте, Телеграм, Инстаграм. Проект «10.000 SEO-советов» в Facebook.
Мои личные аккаунты: Фейсбук, вКонтакте
Мои контакты: Skype: topbase.ru | E-mail: topbase@yandex.ru
Пишите — я всегда рада обратной связи!
Получайте анонсы подобных постов себе на почту
Подпишитесь и получайте не чаще, чем раз в неделю что-нибудь интересненькое из SEO, продвижения сайтов, интернет-магазинов, заработка на сайтах.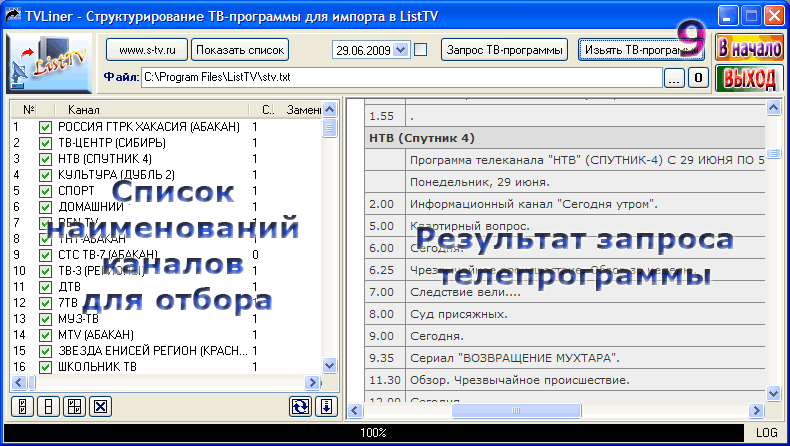
Я, автор этого проекта — Анна Ященко, ищу, тестирую и фильтрую для вас только лучшее!
Вы успешно подписались!
Что-то пошло не так..
Я уважаю ваше личное пространство и выполняю свои обязательства присылать только самое интересное и важное, что я нахожу и использую
Самая нужная программа на свете / Хабр
Какими программами постоянно пользуются люди? Если подумать над этим вопросом, то окажется, что список этот не такой уж большой. К постоянно используемым программам можно отнести: саму операционную систему, файловый менеджер, текстовый редактор, браузер, мессенджер. Это именно тот базовый набор, которым пользуется на компьютере практически каждый человек. Требования к таким программам должны быть высокими: безотказная работа, быстрое выполнение всех функций, понятный и удобный интерфейс.
Можно сказать, что вышеперечисленный набор программ — это самые нужные программы, которыми пользуется человек в цифровую эпоху. Этот список покрывает все базовые потребности человека-пользователя. Или не все? Есть ли еще одна базовая потребность, которая не учтена в вышеприведенном списке самых необходимых программ? Является ли эта потребность самой важной из тех, что должен автоматизировать компьютер? Для меня такая потребность есть, но в списке самых используемых программ ей места не нашлось. Что же это за потребность?
Или не все? Есть ли еще одна базовая потребность, которая не учтена в вышеприведенном списке самых необходимых программ? Является ли эта потребность самой важной из тех, что должен автоматизировать компьютер? Для меня такая потребность есть, но в списке самых используемых программ ей места не нашлось. Что же это за потребность?
Историческая ретроспектива
Ранее компьютер считался устройством для проведения вычислений. Даже бытовые старые компьютеры ориентировались на очень продвинутого пользователя, который использовал компьютер для вычислений путем написания собственных небольших программ. Для полноценной работы с компьютером, пользователь должен был знать язык программирования. Дальнейший взлет более продвинутых компьютерных платформ произошел во многом благодаря появлению первых вариантов электронных таблиц, которые тоже были нацелены на вычисления, но снижали требования к пользователю, не заставляя его быть программистом. В любом случае, это был период, когда назначение компьютера напрямую соответствовало его названию. Сам вычислительный модуль — процессор — ставился во главу угла, ведь именно появление микропроцессора сделало возможным появление самого компьютера.
Сам вычислительный модуль — процессор — ставился во главу угла, ведь именно появление микропроцессора сделало возможным появление самого компьютера.
Однако, последующее развитие не зациклилось на улучшении характеристик процессоров. Развивались все компоненты компьютера, и, в частности, память. Память оперативная, и память постоянная. В тот момент, когда стало ясно, что компьютер способен хранить и быстро доставать невиданные объемы данных, появилась возможность реализовать на компьютере другую давнишнюю мечту человека: накопление и быстрое извлечение данных. Сделать как бы безграничную память, некоторое место, в которое можно положить информацию, а потом быстро ее найти и извлечь. Так стали развиваться базы данных и языки запросов.
Постепенно появилась самая большая в мире база данных — Интернет, со всеми его миллиардами сайтов: википедиями, библиотеками, форумами и соцсетями. Инструменты поиска кардинально поменялись, а обычный пользователь даже не может иметь личный поисковик в Интернете — это практически невозможно, да и не нужно.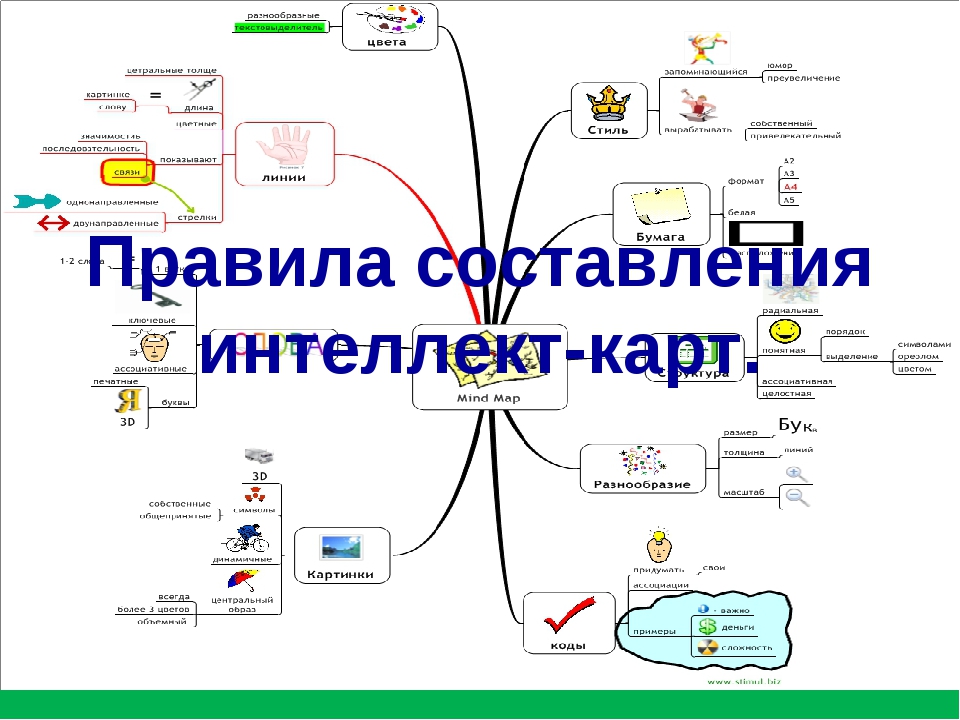
Много ролей примерил на себя компьютер за все годы развития ИТ. Компьютер — это очень универсальная вещь, а цифровая вселенная способна вместить в себя все проявления человеческой фантазии. И хорошо, что к настоящему времени сформировался тот необходимый минимум программ, который демонстрирует эволюционный путь, который прошло человечество в своих потребностях в цифровую эпоху. Потребности эти, честно говоря, сильно сдвинуты в область потребления и передачи контента. Не сказать что это плохо, но…
За всем этим буйством технологий немного в сторону отошла одна очень важная мечта многих людей с древности и до наших дней, которая хорошо реализуется в форме персонального компьютера. Эта мечта — заполучить персонального интеллектуального помощника с бесконечной памятью, который бы помогал человеку если не мыслить, то вспоминать и находить те знания (а не данные!), которые человек уже успел осмыслить, или хотя бы бегло видел краем глаза, или знал, что нечто нужное есть в некоторой библиотеке.
История знает как минимум один концептуальный проект, в котором впервые была предпринята попытка решить вышеозначенную проблему на новом технологическом уровне. Американский инженер-разработчик аналоговых компьютеров Вэнивар Буш предложил отойти от тетрадей с записями, картотек, библиотек, и толпы личных секретарей к устройству, которое бы все это смогло заменить. Он предложил в 40-х годах прошлого века концепцию устройства MEMEX.
… электромеханическое устройство, позволяющее создать автономную базу знаний, снабжённую ассоциативными ссылками и примечаниями, которые могут быть в любое время переданы в другие такие же базы знаний. Это устройство должно было максимально точно имитировать ассоциативные процессы человеческого мышления, при отсутствии недостатков, таких как «забывание» информации.
Описание этого устройства в конечном счете косвенно повлияло на появление гипертекстовой разметки HTML, но нас сейчас интересует именно класс программ, которые в каком-то виде реализовали бы идею этого концепта. Следует обратить внимание на слова «автономная база знаний» — они для нас являются ключевыми. Есть ли программы, попадающие под такое определение? Конечно есть! Это менеджеры персональной информации (PIM), mind-map решения, некоторые органайзеры и их различные гибриды.
Поиск идеального помощника
Особенность выбора идеального персонального помощника состоит в том, что такая программа выбирается на десятилетия. А это требование налагает большие ограничения на возможных кандидатов.
А это требование налагает большие ограничения на возможных кандидатов.
В силу моих убеждений, при поиске подходящей программы я ориентировался в первую очередь на кроссплатформенность и открытость кода. Первое требование — кроссплатформенность — связана с тем, что на домашних компьютерах я использую Linux, а на работе мне предписано использовать Windows, и на какой платформе мне придется работать завтра — я точно не знаю. Но знаю точно, что на каждой платформе мне нужен один и тот же помощник. Открытость кода связана со многими факторами, но самый главный — это безопасность во времени и в пространстве кода. Безопасность во времени — это твердая уверенность, что завтра автор проприетарной программы не закроет свой проект или не поднимет цену лицензии. Безопасность в пространстве кода — это уверенность, что программа не сольет хранимые личные данные в места, где этим данным делать нечего.
Конечно, существенным фактором является и открытость формата хранимых данных. Ничто не должно мешать «бегству с формата», если по каким-то причинам изначальный выбор помощника был неудачным. Очень было бы неприятно расстаться с накопленной базой знаний просто потому, что она хранится в закрытом проприетарном формате.
Очень было бы неприятно расстаться с накопленной базой знаний просто потому, что она хранится в закрытом проприетарном формате.
Примечание: почему я использую термин «база знаний» а не «база данных»? Потому что хотелось бы накапливать именно знания, а не данные. Вопрос в том, каков механизм превращения данных в знания. В общем случае можно сказать, что данные превращаются в знания после их осмысления человеком. Именно после этого мыслительного процесса человек, глядя на знакомые записи (данные) может использовать их в качестве знаний.
Как выяснилось, программ, удовлетворяющих вышеозначенным критериям, не так уж много. И я даже поначалу сильно снизил планку требований, сказав себе, что в крайнем случае есть Wine, да и чего пугаться закрытых форматов — другие же пользуются. И я перебрал большое количество проектов, чтобы понять, что же мне таки лучше всего подойдет.
Из проприетарных продуктов я пересмотрел линейные и древовидные PIM-менеджеры, попробовал mind-map решения, пощупал возможность вести записи в органайзерах.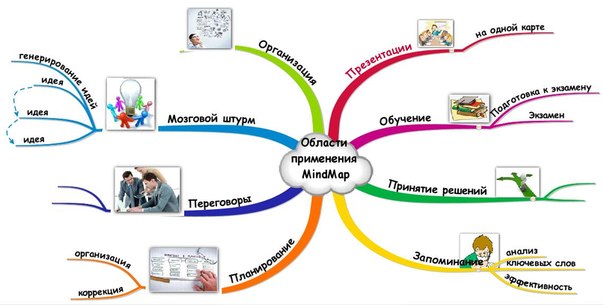 Ничего из испробованного мне не подошло: всегда был какой-нибудь неприятный изъян, который останавливал меня в дальнейшем использовании продукта. Хороший редактор текста, но линейность записей вместо древовидности. Наличие древовидности, но ужасный редактор. Попытки сделать ограниченный набор типов записей, не описывающий все многообразие возможных ситуаций. Невозможность получать данные от офисных программ или из окна браузера. Падения в течении пяти минут при элементарных действиях. Непродуманный интерфейс, сильное загромождение рабочей области, налезание элементов друг на друга в русифицированных версиях. Возможно, что сейчас дела обстоят лучше, но восемь лет назад я ужаснулся тому, что предлагают людям купить за деньги. По сути, из всего зоопарка более-менее доделанными оказался Microsoft OneNote и какой-то китайский комбаин с кучей функций и кнопочек, которые, на удивление, все работали (возможно это был TreeDBNotes). Но видя, каким деструктивным маркетингом занимается Микрософт, связываться с OneNote я не стал.
Ничего из испробованного мне не подошло: всегда был какой-нибудь неприятный изъян, который останавливал меня в дальнейшем использовании продукта. Хороший редактор текста, но линейность записей вместо древовидности. Наличие древовидности, но ужасный редактор. Попытки сделать ограниченный набор типов записей, не описывающий все многообразие возможных ситуаций. Невозможность получать данные от офисных программ или из окна браузера. Падения в течении пяти минут при элементарных действиях. Непродуманный интерфейс, сильное загромождение рабочей области, налезание элементов друг на друга в русифицированных версиях. Возможно, что сейчас дела обстоят лучше, но восемь лет назад я ужаснулся тому, что предлагают людям купить за деньги. По сути, из всего зоопарка более-менее доделанными оказался Microsoft OneNote и какой-то китайский комбаин с кучей функций и кнопочек, которые, на удивление, все работали (возможно это был TreeDBNotes). Но видя, каким деструктивным маркетингом занимается Микрософт, связываться с OneNote я не стал.
В стане свободного программного обеспечения я потрогал CherryTree, Zim, KOrganizer, KeepNote, даже пробовал использовать Eclipse в отдельной директории, создав дерево поддиректорий и открывая в нем текстовые и HTML файлы. Проблемы оказались те же самые: крупные и мелкие недоработки, мешающие полноценно пользоваться программой, либо большие неудобства вместо работы как в случае с Eclipse (не предназначен он для таких вещей, да и сильно тормозит, ибо Java). Даже более-менее приличная CherryTree, например, не могла свернуться в систрей при клике по крестику в заголовке окна: она просто завершала работу. Под Linux я как-то проблему решил, а в Windows она оказалась нерешаема. В свое время я отказался от WinAmp, когда он вдруг разучился сворачиваться и продолжать работать при клике на крестик. Ведь личный помощник — это такая вещь, которая всегда должна быть под рукой, и не должно быть опасений, что он закроется при естественных элементарных действиях.
Ведь личный помощник — это такая вещь, которая всегда должна быть под рукой, и не должно быть опасений, что он закроется при естественных элементарных действиях.
Кстати, о древовидности. Человеческий мозг привык все классифицировать. В этом его сила. Например, такая сложная вещь как классификация живых существ от Аристотеля и Теофраста до Роберта Гука и Карла Линнея и до наших дней имеет древовидную структуру. И хоть по современным представлениям, происхождение видов является, больше не деревом а графом, а электронные энциклопедии при структуризации информации вообще исключают древовидность, что вместе косвенно говорит о том, что дерево непригодно для описания всех возможных группировок данных, я все же считаю, что дерево — это тот удобный компромисс между простотой линейностью (как в первых версиях Evernote) и сложностью графа (как в Википедии). Как минимум, при построении дерева всегда можно выделить один условно главный признак, по которому можно производить группировку информации.Зато наличие дерева дает ту опору, благодаря которой можно искать информацию «по логике вещей», если таковая логика прослеживается.
 Зато наличие дерева дает ту опору, благодаря которой можно искать информацию «по логике вещей», если таковая логика прослеживается.
Зато наличие дерева дает ту опору, благодаря которой можно искать информацию «по логике вещей», если таковая логика прослеживается.Дерево имеет много других полезных свойств: вырастание вверх без существенного утолщения, иерархичность, наглядность. Из дерева легко можно сделать граф: достаточно просто добавить связи между ветками.
Создание идеального помощника
В общем, я очутился в классической ситуации: хочешь получить что-то хорошее — сделай это сам. В тот момент я присматривался к плюсовому фреймверку Qt, который вышел в своей 4-й версии. И я решил, что нет ничего лучше, чем сделать свой собственный менеджер, который бы удовлетворял меня в меру моих собственных способностей. Даже если проект «не пойдет», я, как минимум, смогу на практике изучить перспективный кроссплатформенный фреймверк.
Я прочитал пару книжек, засел за программирование, и сделал первую минимальную версию программы. Я назвал её MyTetra. Выглядела она вот так:
Изначально я точил те мелочи, которых мне не хватало в других менеджерах: нормальное сворачивание в трей, разделение дерева на сущности «ветка» и «запись», подсчет количества записей в ветках, копипаст записей через буфер обмена. В первой версии даже не было поиска, но я начал наполнять базу своими записями, чтобы прочувствовать, можно ли удержать информацию в дереве, не уткнусь ли я в то, что мне потребуются различные «срезы» дерева (в необходимости автоматически реконфигурируемого дерева меня страстно убеждал один товарищ), возникнет ли необходимость группировки по разным признакам. И быстро понял, что дерево свою функцию «базиса» хорошо выполняет, особенно, если ты сам вырастил это дерево.
В первой версии даже не было поиска, но я начал наполнять базу своими записями, чтобы прочувствовать, можно ли удержать информацию в дереве, не уткнусь ли я в то, что мне потребуются различные «срезы» дерева (в необходимости автоматически реконфигурируемого дерева меня страстно убеждал один товарищ), возникнет ли необходимость группировки по разным признакам. И быстро понял, что дерево свою функцию «базиса» хорошо выполняет, особенно, если ты сам вырастил это дерево.
Формат хранения данных я изначально делал в «естественном» виде, и никаких собственных бинарных форматов использовать не собирался. Так же отказался от хранения данных в БД. Все форматы открытые: дерево хранится в XML-файле, форматированный текст — в HTML, картинки в PNG, настройки в INI. Изначально структура проектировалась так, чтобы данные были аккуратно разложены по файлам, и поддавались дифференциальной синхронизации через системы контроля версий. Имена хранимых файлов и директорий сделаны платформонезависимыми: все-таки кроссплатформенная программа должна работать на любой современной платформе без переделок и побочных эффектов.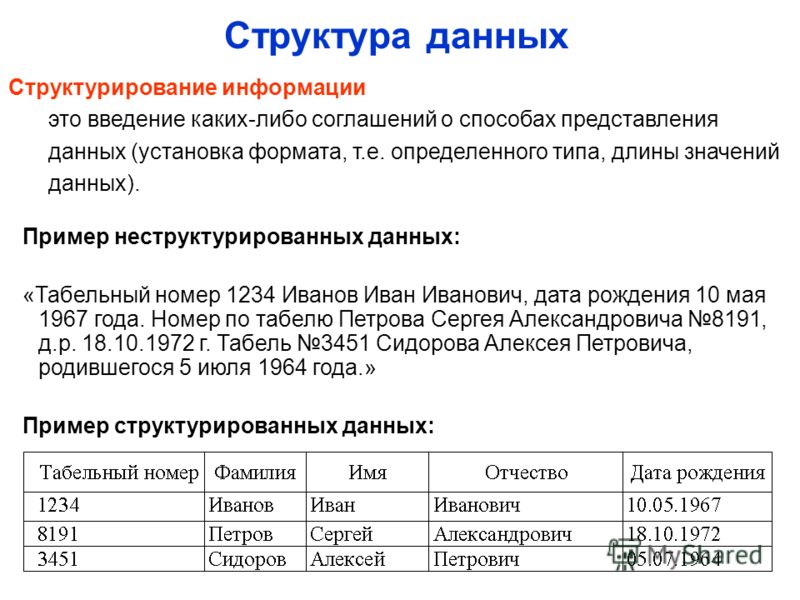 Всё это элементарные вещи, но оказывается, разработчики похожих программ не всегда их понимают: например автор OutWiker позволяет давать каталогам русскоязычные названия — то есть, использует в качестве имени каталога на диске имя ветки, причем со знаками препинания, что меня в свое время сильно потрясло: программа на Питоне заявлялась как кроссплатформенная, но при синхронизации данных с разных платформ такое решение обязательно бы вызвало проблемы.
Всё это элементарные вещи, но оказывается, разработчики похожих программ не всегда их понимают: например автор OutWiker позволяет давать каталогам русскоязычные названия — то есть, использует в качестве имени каталога на диске имя ветки, причем со знаками препинания, что меня в свое время сильно потрясло: программа на Питоне заявлялась как кроссплатформенная, но при синхронизации данных с разных платформ такое решение обязательно бы вызвало проблемы.
Для сущностей «ветка» и «запись» я определил основные действия, которые с ними можно выполнять: создание, редактирование, копирование, вставка, перемещение, удаление. И когда этот минимум полностью заработал и появился поиск, я немного причесал код и выпустил первую публичную версию.
Что я записывал в свою программу? Первым делом я стал записывать такие сведения, которые все время забывал, и найти которые в простом виде очень трудно. Есть такие вещи, за которыми постоянно лезешь в свои записульки. Например, в Linux man-страницы традиционно пишутся в форме «минимально необходимого и достаточного», поэтому, быстро понять опции командной строки какой-нибудь программы очень сложно.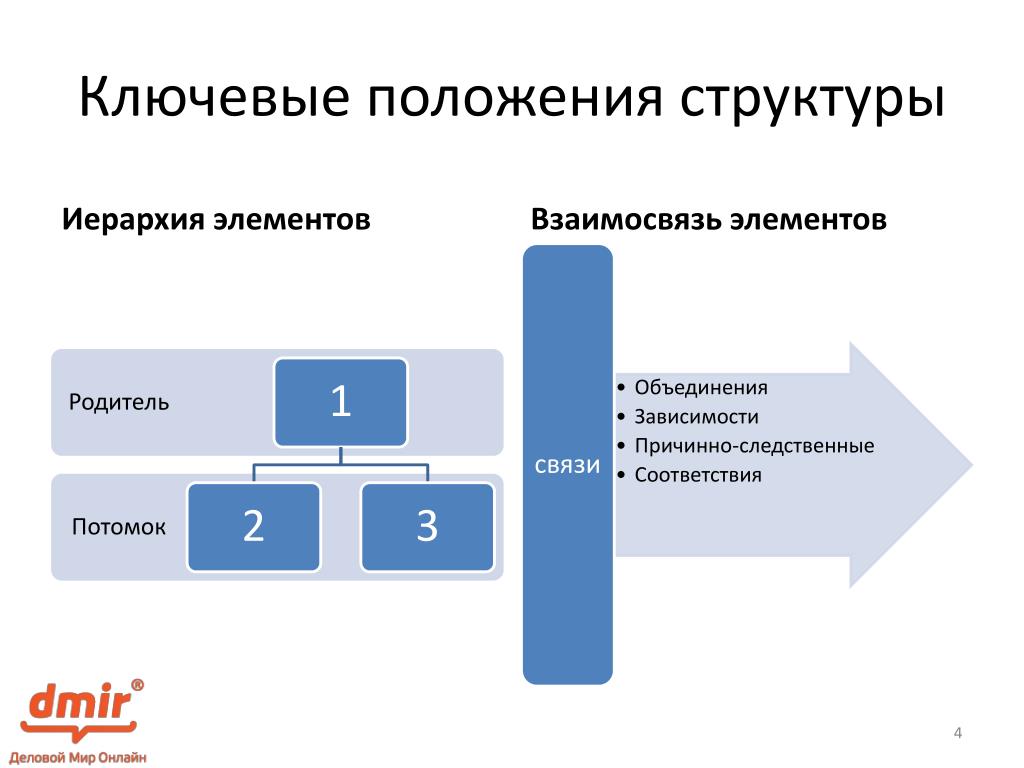 К примеру, опции упаковки tar.gz архива: четыре плохо произносимые буквы, которые вечно забываешь.
К примеру, опции упаковки tar.gz архива: четыре плохо произносимые буквы, которые вечно забываешь.
Так же стал подробно записывать действия, которые произвожу при настройке какого-нибудь линухового софта. Часто в Linux сложно не только настроить программу, а сложно ее установить, не говоря уже о запустить. И чтобы программа завелась, надо сделать не пять и не пятнадцать неочевидных действий, а гораздо больше. К концу, если что-то получилось, человек уже не помнит точно, что он делал в начале. А если записывал — то такой проблемы нет.
Еще я себе записывал действительно хорошие материалы из Интернет или «выжимки», которые делал на их основе. Бывает так, что долго не можешь разобраться в каком-либо вопросе. И вдруг натыкаешься на текст, в котором все подробно, легко и просто объясняется. Жалко такой текст потерять: он может исчезнуть из интернета, о нем можно просто, заработавшись, забыть. Но если скинуть его в свою базу знаний, то можно испытать чувство успокоения, что эти важные сведения никуда не денутся, и останутся с вами. Честно говоря, я не понимаю людей, которые делают закладки в браузере: неприятно делать закладки и знать, что в какой-то момент информация может исчезнуть. Несколько раз меня моя предусмотрительность выручала: интересный материал исчезал из интернета, зато оставался в моей базе.
Честно говоря, я не понимаю людей, которые делают закладки в браузере: неприятно делать закладки и знать, что в какой-то момент информация может исчезнуть. Несколько раз меня моя предусмотрительность выручала: интересный материал исчезал из интернета, зато оставался в моей базе.
И конечно, я записывал всю возможную информацию по своим бытовым электронным устройствам, пароли входа в админки и прочие интернет-сервиса, телефоны и адреса всяких организаций и знакомых, прочую мелочевку, которая очень важна, но сложно запомнить.
Постепенно база росла, а программа видоизменялась. В настоящий момент она выглядит вот так (кстати, это скриншот из Linux, а не Windows):
Да, учитывая, что сейчас легко доступны хостинги распределенных систем контроля версий, такие как GitHub и BitBucket, а так же облачные хранилища типа DropBox или Яндекс.Диск, грех бы было ими не воспользоваться для бесплатного хранения в них своих баз знаний. Заодно решался вопрос бекапа и синхронизации. Возникала только одна проблема: хранение приватных данных.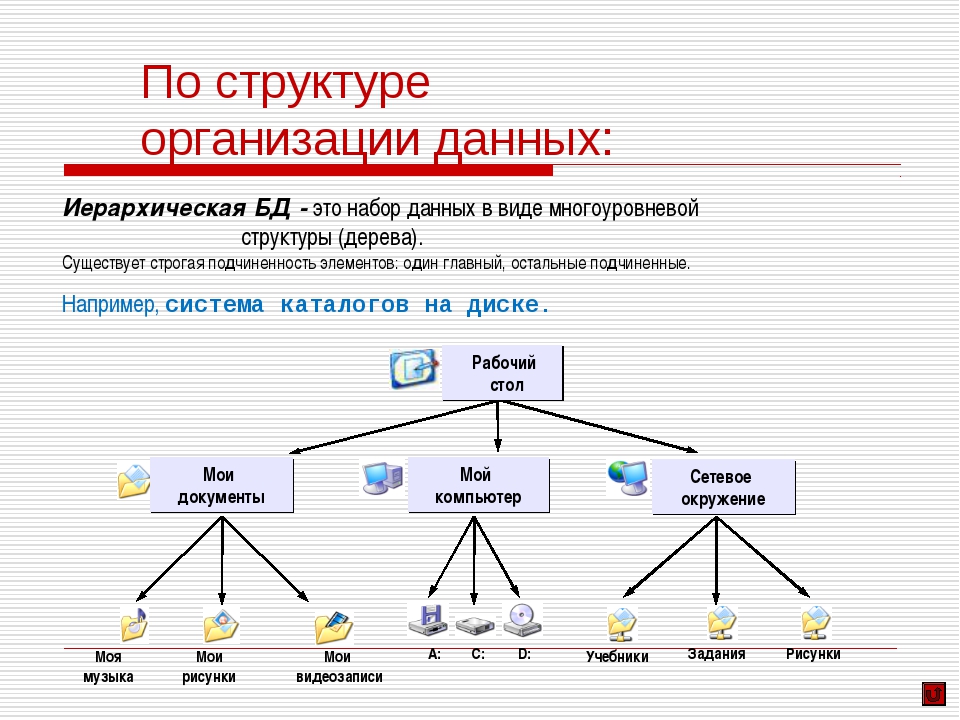 В открытом виде их нельзя загружать на хостинг. Поэтому была разработана небольшая криптографическая библиотека, и на ее основе сделано шифрование выбранных веток. То есть, появилась возможность безопасного хранения приватных данных у всех на виду. Почему была сделана библиотека, а не использована существующая? Потому что менеджер позиционируется как Qt-only. Он должен легко собираться командами qmake & make на любой платформе, где есть только Qt, и никаких дополнительных библиотек не требовать. Такой принцип позволяет легко получать сборки для всех популярных платформ: Linux, Windows, MacOs, FreeBSD, Android, и даже под такую экзотику как MeeGo. Впрочем, в формате шифрования предусмотрено версионирование, и, возможно, я когда-нибудь прикручу OpenSSL, когда разберусь как ее включать в проект для всех вышеперечисленных платформ.
В открытом виде их нельзя загружать на хостинг. Поэтому была разработана небольшая криптографическая библиотека, и на ее основе сделано шифрование выбранных веток. То есть, появилась возможность безопасного хранения приватных данных у всех на виду. Почему была сделана библиотека, а не использована существующая? Потому что менеджер позиционируется как Qt-only. Он должен легко собираться командами qmake & make на любой платформе, где есть только Qt, и никаких дополнительных библиотек не требовать. Такой принцип позволяет легко получать сборки для всех популярных платформ: Linux, Windows, MacOs, FreeBSD, Android, и даже под такую экзотику как MeeGo. Впрочем, в формате шифрования предусмотрено версионирование, и, возможно, я когда-нибудь прикручу OpenSSL, когда разберусь как ее включать в проект для всех вышеперечисленных платформ.
Помимо шифрования, в программе была реализована настраиваемая синхронизация, навигация по истории, встроенный довнлоадер, прикрепляемые файлы, сортируемый список записей и много еще чего нужного. Спустя пять лет открытой разработки, получился PIM-менеджер с теми характеристиками, которые были нужны: открытый, кроссплатформенный, легкий и быстрый, способный работать месяцами не выключаясь, с набором функционала, который необходим для удобной работы по ведению записей.
Спустя пять лет открытой разработки, получился PIM-менеджер с теми характеристиками, которые были нужны: открытый, кроссплатформенный, легкий и быстрый, способный работать месяцами не выключаясь, с набором функционала, который необходим для удобной работы по ведению записей.
Я, как человек, ежедневно пользующийся MyTetra, к настоящему времени держу в ней порядка 5000 записей. Средний прирост — около 1000 записей в год. Для сравнения: автор сервиса Evernote Степан Пачиков в одном из своих интервью обмолвился о 20000 записей. Однако у него другой концепт: он собирает в свою систему все подряд, используя ее как «внешнюю» человеческую память. Я же собираю нужную мне информацию, оформляю ее, тегирую, т. е. работаю с информацией руками. И за последние три года накопилась вот такая статистика:
Не каждый может похвастаться таким Contributions Map на GitHub-е. А я даже не замечаю, как эта статистика набралась, так как MyTetra — это мой ежедневный рабочий инструмент.
MyTetra и Интернет
Менеджер персональных записей — это, конечно, хорошо. Каждый может сделать свой маленький огородик и втихомолку пилить свою базу знаний. Сколько в такой базе личных данных, а сколько таких, которые, возможно, были бы нужны другим людям? По своему опыту скажу, что записей, которыми можно делиться, примерно 2/3 от общего числа. Это с учетом того, что в приватных записях у меня идет постоянная ежедневная работа, т. е. их процент у меня очень большой.
Каждый может сделать свой маленький огородик и втихомолку пилить свою базу знаний. Сколько в такой базе личных данных, а сколько таких, которые, возможно, были бы нужны другим людям? По своему опыту скажу, что записей, которыми можно делиться, примерно 2/3 от общего числа. Это с учетом того, что в приватных записях у меня идет постоянная ежедневная работа, т. е. их процент у меня очень большой.
Как то раз я игрался с визуализацией моей базы через пакет GraphViz. И для понимания масштаба моих открытых данных, сделал пару картинок. Здесь на сводной картинке облако повернуто на 90 градусов, иначе оно выглядело бы слишком широким. Здесь отображено около 3000 открытых записей. Полная база была бы на ~2000 записей больше.
Ссылки на полноразмерные картинки (Внимание! Картинки очень большие, браузер может сегфолтнуться. Лучше выкачать и посмотреть просмотрщиком.):
Дерево PNG 1.751 x 32.767 pix (7.2 Мб)
Облако PNG 31.279 x 5.289 pix (19.2 Мб)
Жалко, что большие массивы знаний просто лежат на дисках пользователей, и у них нет даже возможности поделиться ими, даже если бы они и захотели, потому что нет соответствующей инфраструктуры.
Какой резон пользователям делиться своими базами знаний? Это каждый решает сам для себя. Кто-то хочет «вернуть долги» информационному сообществу, кто-то просто считает, что на пути восхождения каждый человек должен делиться своими знаниями. Кто-то испытывает потребность улучшить свою карму. Кто-то хочет это делать просто из альтруистических соображений, а кто-то из практических: удобно заглянуть в свои открытые записи из любого места, где есть Интернет.
В общем, помимо самой программы накопления записей я решил сделать сервис, позволяющий выводить свои записи в пространство Интернет. Первоначально я сделал JavaScript-приложение, которому можно скормить URL индексного файла базы MyTetra, доступного по HTTP(S). И это приложение открывает базу MyTetra в WEB-интерфейсе, напоминающем Qt-интерфес MyTetra. Я назвал это приложение
MyTetra Web Client. Выглядит это дело вот так:
Этот клиент был написан в 2012 году, и с тех пор я его не развивал. Это очень простая оболочка, в которой не сделано даже поиска по названию записей и тегам. Просто демонстрация того, что базу MyTetra можно увидеть в браузере прямо в Интернете, если хранить данные в открытых репозитариях GitHub или BitBucket. Клиент работает и сейчас, а увидеть демонстрацию его работы можно так:
Это очень простая оболочка, в которой не сделано даже поиска по названию записей и тегам. Просто демонстрация того, что базу MyTetra можно увидеть в браузере прямо в Интернете, если хранить данные в открытых репозитариях GitHub или BitBucket. Клиент работает и сейчас, а увидеть демонстрацию его работы можно так:
- Скопируйте в буфер обмена следующий URL: https://raw.github.com/xintrea/mytetra_syncro/master/mytetra.xml
- Перейдите по ссылке Web Client, и вставьте этот URL в появившемся диалоге. (Иногда GitHub не отвечает из-за большого количества запросов с IP моего сайта, поэтому если ничего не показывается, можно повторно нажать кнопку «Set URL» вверху справа)
Если есть другая база MyTetra, хранимая где-то в открытом HTTP(S) доступе — GitHub, BitBucket, расшаренный каталог DropBox, то можно увидеть и ее, достаточно указать URL файла mytetra.xml. Никакой регистрации не требуется — все просто работает. Если в базе есть приватные зашифрованные ветки, то они просто не отображаются: нет никакого смысла показывать людям то, что невозможно прочитать.
Однако у этого веб-клиента имеется один недостаток: по сути, это просто JavaScript-страница, и отображаемые на ней данные не индексируются поисковиками. Какой толк от баз знаний, если о них никто не знает?
Поэтому я сделал второй проект, который называется MyTetra Share. Девиз проекта: «Делитесь знаниями!». Этот сервис динамически преобразует базу знаний MyTetra в набор HTML-страниц, которые можно просматривать через Интернет. На официальной страничке проекта перечислено 8 баз пользователей, которые можно сразу просмотреть. Принцип такой же как у MyTetra Web Client: если база хранится в открытых репозитариях, можно сформировать специальный URL, по которому откроется содержимое базы знаний в HTML-виде. Если поисковик проиндексирует такой URL, значит он пойдет дальше и проиндексирует все содержимое открытой базы данных. Как я уже сказал, таких баз сейчас 8 (пример одной базы), и они проиндексированы поисковиками. Выглядит MyTetra Share следующим образом. Само дерево:
И запись:
Этот проект оказался более востребованным, и я с помощью него даже смог монетизировать содержание своего хоумпейджа и сервиса MyTetra Share: на некоторых страницах можно заметить текстовую рекламу. Этих средств хватает на оплату хостинга, доменного имени и оплаты мобильного телефона. Можно было бы зарабатывать больше, но я сразу поставил жесткий фильтр на всякие аудио-наркотики, игровые автоматы, вибраторы, микрозаймы, на колдунов и экстрасенсов. К сожалению, даже в текстовой рекламе основные прибыли идут с мракобесия и разврата. Я же занимаюсь выравниванием цифровой вселенной в более правильное русло, поэтому такие вещи на моем сайте не допустимы.
Этих средств хватает на оплату хостинга, доменного имени и оплаты мобильного телефона. Можно было бы зарабатывать больше, но я сразу поставил жесткий фильтр на всякие аудио-наркотики, игровые автоматы, вибраторы, микрозаймы, на колдунов и экстрасенсов. К сожалению, даже в текстовой рекламе основные прибыли идут с мракобесия и разврата. Я же занимаюсь выравниванием цифровой вселенной в более правильное русло, поэтому такие вещи на моем сайте не допустимы.
Благодаря размещению хорошо протегированной информации, проект MyTetra Share сформировал для сайта индекс цитирования в 100 ТИЦ, и обеспечил около 3000 посетителей в сутки. Для Pet-проекта это не полохие показатели, учитывая что никакой раскруткой я не занимался.
О несбывшихся надеждах
Какие же надежды я возлагал на этот гигантский и многолетний проект? Самое главное, чего я хотел от проекта — это формирование хоть небольшой, но постоянной команды разработчиков, чтобы можно было развиваться не как программист-одиночка, а в плотном общении с себе подобными. Вторая надежда была на то, что я смогу разобраться с языком C++, и наконец-то почувствую легкость в программировании на нем. К сожалению, ни того ни другого не произошло.
Периодически появлялись люди, которые делали небольшие правки и багфиксы в проекте. И я им очень благодарен. Иногда они делали что-то для проекта сами, без просьбы, иногда я сам обращался к сообществу ЛОРа и Тостера, и находились люди которые помогали решить конкретную проблему. Но это всё единичные случаи, весь проект приходится тянуть самому.
Что касается языка C++, то он оказался гораздо сложнее и неоднозначнее, чем я мог предположить десять лет назад, когда начинал его плотно использовать. К сожалению, моя работа не связана с программированием: там, где я живу, такой вещью не заработаешь. В моем окружении нет знакомых, кто хотя бы знал разницу между «сями» и «плюсами», только пара PHP кодеров. И так получается, что если нет личного общения ртом и ушами с доской и фломастером под рукой, то нет и развития. Не с кем обсудить сложные вещи так, чтобы не осталось недопонимания и они хорошо уложились в голове. Возможно, мне помогли бы книги, которые мне очень рекомендовали:
- Николас А. Солтер, Скотт Дж. Клепер, «C++ для профессионалов»
- Брюс Эккель, «Философия С++» (1-й том)
- Брюс Эккель, «Философия С++. Практическое программирование» (2-й том)
но я нигде не могу найти их в бумажном виде. С экрана же глубокого чтения у меня не получается. Максимум что могу читать — художественную литературу с книгочиталки. Но техническую не воспринимаю. Возможно потому, что книгочиталки — это один «лист», а мне нужно быстро прыгать вперед-назад в поисках разных мест, но книгочиталки такого не позволяют, слишком они медленные и неудобные.
Я пытался улучшить понимание C++ просмотром лекций из курсов удаленного обучения. Самое вменяемое, что я нашел — это курсы Евгения Линского на lektorium.tv. Но все равно, лекции по интернету к учебе отнести нельзя: у видео не спросишь те вещи, которые тебе были непонятны по ходу лекции. Так что толку от такого «обучения» немного.
В общем, для меня язык C++ так и остался загадкой. Я использую очень малую часть языка — процедуры и ООП, с болью пишу шаблоны, если без них не обойтись. Каждый раз плачу от синтаксиса указателей и адресов. С осторожностью использую наследование, хотя понимаю, что сила языка именно в нем. С ужасом смотрю на множественное наследование и на кастинг типов объектов. Qt немного сглаживает все эти проблемы, но он их больше маскирует, чем решает. Апофеозом моего понимания языка стала новость на ЛОРе, которую быстро выпилили, вот небольша часть:
Какие изменения предлагает инициативная группа стандарта C++!!, чтобы сделать язык C++ красивым, мощным и востребованным средством современной разработки? Из наиболее заметных улучшений:
- Включение в стандарт концепторов, реализующих аспектно-ориентированную парадигму наследуемого кода;
- Многовекторная диспетчеризация динамического полиморфизма для трансляции полиморфного интерфейса в рантайм;
- Нативная поддержка каппа-функторов, и отображение их на множества булеан с ковариантной структурой, решающая проблему единичности метаданных;
- Рекуррентные конструкторы, реализующие перезагрузку объектов-функций для дружественных родовых классов;
- Расширенная арифметика указателей для поддержки адресации фрагментов унаследованных виртуальных структур данных в спецификаторе сборки;
- Трансформация мутабельных объектов через операторы доступа к полям класса посредством лаяй-генераторов.
Чтобы стало понятно — эту новость я писал
на 1 апреля, и в ней написана просто мешанина терминов. Примерно такое у меня восприятие языка. Самое смешное, что почти никого вышенаписанная белиберда не смутила — народ активно обсуждал действия комитета ISO и угарал над названием C++!!..
Как вы можете помочь проекту
О том, что появятся люди, помимо меня
постояннозанимающиеся кодом проекта, я даже не мечтаю. За все время развития проекта было несколько человек, которые продержались чуть дольше чем люди, делающие единичные правки. Но их энтузиазм быстро сходит на нет, когда приходит осознание, что перед тем как кодить, надо согласовывать изменения. Возможно, когда-нибудь чудо произойдет, и у меня появятся постоянные напарники.
Поэтому, реальная помощь проекту MyTetra может заключаться только в одном: нужно начать им пользоваться. Если вы настроите синхронизацию, и начнете пользоваться MyTetra Share, то у вас получится удивительная вещь: вы накапливаете свою базу знаний, и автоматически делитесь знаниями со всем Интернетом, просто пользуясь этим самоорганизовывающим инструментом. Можно пользоваться MyTetra Share втихую для себя, а чтобы ссылка на базу появилась на странице проекта, можно сообщить об этом желании автору MyTetra. О том как настроить синхронизацию через Интернет, написана отдельная статья.
Важно понимать: если вы пользуетесь бесплатными тарифами CVS-хостингов типа GitHub или BitBucket, то при начале пользования вы принимаете правила хостинга о том, что ваши данные являются открытыми для всех под различными OpenSource лицензиями. Соответственно, ваши данные могут появиться на страницах MyTetra Share просто по факту их размещения на таких открытых хостингах, без вашего участия. Это суровая правда мира OpenSource, и это есть хорошо!
На официальном форуме можно высказывать свои пожелания по необходимым улучшениям программы. Хоть у меня и есть свое видение функций программы, аргументированные доработки находят свое отображение в коде.
Для того, чтобы проект развивался дальше, мне как создателю, надо видеть, что проект востребован. Никаких объективных средств для определения количества инсталляций программы не предусмотрено: люди не любят, когда программа начинает сливать какую-то информацию, даже если она предварительно спросила разрешения на это. Поэтому единственным мерилом востребованности может быть переписка на форуме, количество email сообщений и наличие активности в MyTetra Share.
Если количество баз в MyTetra Share увеличится вдвое относительно текущего, я начну работу по созданию отдельного сайта для проекта MyTetra. На новом сайте планируется сделать разделы новостей, исходников, Wiki, скриншотов, разместить форум, перенести туда сервисы MyTetra Share и MyTetra Web Client. Возможно, наличие сайта и англоязычных версий страниц выведет проект на новый уровень.
Кстати, об английском языке. Ко мне постоянно обращаются англоязычные пользователи, и я понимаю, что некоторый интерес в англоязычном мире MyTetra имеет. Две официальных страницы — страница MyTetra и MyTetra Web Client имеют англоязычные версии на кривом английском (я много перевожу с, но не могу на). По-хорошему, их надо причесать и привести в соответствие с русскоязычными версиями. Так же требуют перевода страницы по MyTetra Share, по синхронизации данных через Интернет, по формату хранения данных (ссылки приведены в конце этого поста). Кроме того, было бы неплохо заполучить если не звуковую дорожку, то хотя бы англоязычные субтитры к обзорным видео (тоже в конце поста). Я всего этого сделать не могу, но возможно кто-то с хорошим знанием языка возьмется за такую работу.
О форках MyTetra
Автору очень приятно, что несколько месяцев назад китайский разработчик Beimprovised (реальное имя Hugh Young) сделал форк MyTetra, называемый
MyTetra WebEngine. В течении нескольких месяцев он неистово коммитит в GitHub громадные куски кода, что заставляет искренне удивляться его работоспособности. Наличие этого форка говорит о том, что код программы MyTetra был достаточно понятен и прост для того, чтобы другой разработчик, даже являющийся носителем другого языка, смог подхватить проект и начать делать на его основе новый продукт.
У Hugh Young свое видение проекта, и его форк очень далеко ушел от оригинальной MyTetra. Но недавно он высказал сожаление о том, что пути проектов разошлись, и нововведений, появившихся в последней версии MyTetra у него нет, а воспользоваться новым кодом проблематично, потому что он сильно изменил внутреннюю структуру проекта.
В любом случае, наличие форка меня, как автора, очень радует. Это значит, что мои усилия по написанию проекта были не напрасными.
Заключение
О программе MyTetra я написал несколько материалов, позволяющих разобраться с возможностями, заложенными в нее:
Есть хорошая идеологическая статья человека под псевдонимом Игорь Блогератор (к сожалению, я с ним не знаком), во второй части которой рассматривается MyTetra:
Так же, ввиду того, что на днях я выпустил свежую версию 1.42, я сделал видеообзор программы в 3 частях, видеообзор выложен на YouTube:
В этих видео подробно рассказываются все аспекты работы с программой (поэтому видео длинные по 20-40 мин.), и рассматриваются основные приемы работы. MyTetra — это не только менеджер заметок, это инструмент, какорый помогает организовать собственный рабочий процесс. Например, в MyTetra можно вести список дел и создавать для себя небольшие отчеты. Об этой методике рассказывается в первой части.
По новой версии MyTetra 1.42 (юбилейный выпуск на 5-ти летие открытия исходников) опубликована новость, в которой описаны изменения и нововведения, есть информация по установке и обновлению программы.
Надеюсь, сообществу Хабрахабра понравится программа, и идеи, в нее заложенные.
понятие и виды, модели и примеры
Вопросы структурирования информации весьма востребованы в современном мире ввиду того, что пространство перенасыщено различной информацией. Именно поэтому возникает потребность в правильной интерпретации и структурировании большого количества данных. Без этого невозможно принимать важные управленческие и экономические решения, основываясь на каких-либо знаниях.
Общие сведения
Существует очень много методов структурирования информации. Это вызвано тем, что существует также огромное количество способов ее представления и организации. Об этом надо помнить, ведь информация бывает очень различной по свойствам. Большую роль при этом играет то, какие именно средства или каналы восприятия задействуются при вводе или выводе данных, какой уровень структурированности имеет информация изначально и относится ли она к числовому, графическому, текстовому или другому типу. Важнейшую роль играет окончательная цель, ради которой необходимо структурировать данные.
Цели
Анализ и структурирование информации всегда преследуют определенные цели, и на самом деле их довольно много. От правильной постановки цели во многом зависит конечный результат. Отметим главное классы целей:
- Получение новых знаний по определенному процессу.
- Проверка информации на неполноту или противоречивость.
- Необходимость систематизации и упорядочивания знаний.
- Акцентирование внимания на некоторых аспектах.
- Сокращение информации для избавления от перенасыщения.
- Представление информации в более наглядном и понятном виде.
- Использование обобщений и абстракций при описании.
В зависимости от того, какие цели мы преследуем, применяются технологии и методы структурирования. Но как мы знаем, классификация – это не конечный фактор, который определяет метод упорядочивания. Именно поэтому важно определить вид информации и способы ее представления.
Классификация информации
Рассмотрим классификацию по сущности и содержанию знаний:
- О целях и ценностях для нужд планирования и прогнозирования.
- О функциональных особенностях.
- О структуре.
- О динамических изменениях.
- В целом о состоянии.
- О задачах.
Данная классификация представлена в порядке убывания актуальности. Так, наиболее важной является информация о целях, ведь именно исходя из нее определяются конечные потребности пользователя. Остальные же классы сравнительно независимы друг от друга, они лишь позволяют уточнять и дополнять уже имеющиеся данные для отражения их полноты. Такое размещение вполне обоснованно, потому что дает возможность решать быстро и эффективно прикладные задачи, но практически не применяется при решении сложных задач, требующих компьютерного анализа.
Основы классификации и структурирования информации базируются и на других признаках:
1. Информация, имеющая отношение к чему-либо
- К объекту.
- К нескольким объектам.
- К среде.
2. Привязка к временному аспекту
- Прошлое.
- Будущее.
- Настоящее.
3. Класс структурной организации
- Структурированный.
- Неструктурированный.
- Упорядоченный.
- Формализованный.
Несмотря на кажущуюся сложность всех классификаций, хочется сказать о том, что структуризация информации – это простой процесс, который мы воплощаем в жизнь каждый день. Проблема понимания этого вопроса заключается лишь в том, что мы не задумываемся о том, насколько это многогранный и обширный вопрос, делаем все автоматически. Если же погрузиться в исследование этой темы с профессиональной точки зрения, то окажется, что структуризация информации решает множество задач, помогая нам построить собственную систему знаний и использовать ее для дальнейшего развития или решения задач как на бытовом уровне, так и на профессиональном.
Что же такое классификация?
Сбор и структурирование информации невозможно без понятия классификации, которое мы частично рассмотрели в предыдущих абзацах. Но все же стоит подробнее разобраться с этим понятием. Классификация – это некая система информационных элементов, которая обозначает реальные объекты или процессы и упорядочивает их по определенным схожим или различным признакам. Чаще всего это процедура проводится для того, чтобы исследование было более удобным.
Существует два вида классификаций. Первая, искусственная, осуществляется по неким внешним чертам, которые не отражают настоящую сущность объекта, и позволяет упорядочить лишь поверхностные данные. Второй вид – это натуральная или естественная классификация, которая проводится по существенным признакам, которые характеризуют сущность объектов и процессов. Именно натуральная классификация – это научный инструмент, который используют для изучения закономерностей объектов и процессов. При этом нельзя сказать, что искусственная классификация абсолютно бесполезна. Она позволяет решать ряд прикладных задач, но сама по себе довольно ограничена.
От того, насколько качественно была выполнена процедура классификации, во многом зависит дальнейший исход исследования. Это вытекает из того, что разграничение по признакам проводится на ранних этапах, а если на них допустить ошибку, то дальнейшие исследования пойдут некорректным путем.
Важные принципы
Приемы структурирования информации требуют соблюдения определенных принципов, позволяющих быть уверенными в достоверности результатов:
- Необходимость каждую операцию разделить на классы и использовать только один основополагающий признак. Это позволяет отсеять лишнюю информацию и сосредоточиться на основных моментах.
- Полученные группы должны быть логически связанными и выстроенными в определенном порядке по признаку важности, времени, интенсивности и так далее.
Правило Миллера
Закономерность носит название 7 ±2. Ее открыл американский ученый и психолог Джордж Миллер после проведения большого количества экспериментов. Правило Миллера заключается в том, что кратковременная человеческая память способна в среднем запомнить 7 букв алфавита, 5 простых слов, 9 чисел, состоящих из 2 цифр, и 8 десятичных чисел. В среднем это представляет группу в количестве 7 ±2 элементов. Это правило применимо во многих областях, активно используется для тренировки человеческого внимания. Но его также применяют для структурирования информации, опираясь на то, сколько сможет осилить человеческий мозг.
Принцип края
Этот эффект основывается на том, что человеческий мозг лучше запоминает информацию в начале или в конце. Исследованием этого принципа занимался ученый из Германии Герман Эббингауз в XIX веке. Именно он считается его открывателем. Интересно, что в нашей стране об этом принципе узнали после фильма про приключения Штирлица, в котором главный герой использовал его для переключения внимания своего противника.
Эффект Рестрофф
По-другому этот эффект называется эффектом изоляции, и заключается он в том, что когда объект выделяется из ряда похожих, то запоминается гораздо лучше других. Другими словами, можно сказать что сильнее всего мы запоминаем то, что более всего выделяется. Подсознательно этот эффект используют абсолютно все люди, которые хотят, чтобы их заметили. Каждый человек замечал, что это работает, когда, помимо его воли, внимание привлекала яркая одежда, выделяющаяся из толпы, причудливой архитектуры дом, выглядывающий из серой улицы, или красочная обложка из-под груды одинаковых.
Также принцип весьма применим в рекламе, где производители делают все, для того чтобы максимально выделить свой товар. И это работает даже на тех, кто сам знает об этом эффекте!
В структурировании информации эффект Рестрофф используется для того, чтобы различные групп информации были не похожи друг на друга. Это обеспечивает их более быстрое легкое понимание. Таким образом, если каждый элемент будет неоднозначным и интересным, то мы запомним его гораздо быстрее.
Методы структурирования информации
Процесс изучения человеческого мозга не проходит зря. Ученые вывели несколько методик и способов структурирования информации, которые позволяют сделать запоминание намного более удобным. Мы поговорим об основных и самых популярных способах.
Метод римской комнаты, или цепочка Цицерона, – это очень простой, но эффективный метод для усвоения материала. Он заключается в том, что запоминаемые объекты необходимо мысленно расставить в вашей комнате или той, которую вы очень хорошо знаете. Главное условие в том, что все предметы должны быть расставлены в строгом порядке. После этого для того, чтобы вспомнить необходимую информацию достаточно вспомнить комнату. Именно так и делал Цицерон, когда готовился к выступлению. Он гулял по своему дому, мысленно расставляя акценты, чтобы суметь вернуться к важному моменту по ходу своего выступления. Не стоит ограничиваться комнатой, можно попробовать размещать желаемую информацию на знакомой улице, рабочем столе или другом объекте, который вам хорошо известен.
Метод ментальных карт, или метод Бьюзена, – это простой способ графического изображения информации при помощи схем. Часто этот метод называют майндмэппинг, из-за того что необходимо строить ассоциативные карты. Такой способ запоминания стал довольно популярным в последнее время. Подобные карты рекомендуют составлять психологи и различные тренеры для того, чтобы правильно ставить цели и понимать свои настоящие желания. Но первоначальная цель ментальных карт заключалась именно в том, чтобы быстрее запоминать и структурировать информацию. Для того чтобы составить натальную карту, вам понадобится:
- Материал, который вы захотите изучить.
- Большой лист бумаги.
- Цветные ручки и карандаши.
После этого нарисуйте в центре листа символ или рисунок, который ассоциируется с темой, которую вы хотите запомнить, или отображает ее суть. После этого по направлению к центру рисуйте различные цепочки связей, которые отражают ту или иную сторону изучаемого объекта. В результате для того, чтобы вспомнить нужную информацию, вам не придется просматривать списки или читать пол-учебника. Вы сможете сразу вспомнить главную идею, посмотрев на нее в центре листа, а потом, двигаясь по отходящим ветвям, вспомнить конкретно то, что вам нужно.
Методы поэтапной структуризации
Естественно, что структурирование цифровой информации представляет собой более сложный процесс. Особую сложность представляют задачи, которые характеризуются разным уровнем неопределенности. Для того чтобы решить их, следует прибегать к ряду методов, которые можно объединить в методы поэтапной структуризации и морфологические методы. Оба эти вида адаптированы для того, чтобы их можно было использовать в условиях высокой неопределенности.
Но существенным образом они отличаются в том, какой способ будет использоваться. Первая группа нацелена на то, чтобы постепенно снижать неопределенность задачи, в то время как вторая группа нацелена на решение посредством создания моделей за одну итерацию.
Стоит отметить, что при использовании морфологического метода неопределенность может совершенно не меняться, она просто будет перенесена на другой уровень описания. Оба метода начинаются с того, что исследуется уровень формализации. Но если для методов поэтапной структуризации уровень может быть любым, то для морфологических методов важна детальная декомпозиция и последующее генерирование матричных моделей. Другими словами, можно сказать, что морфологические методы чаще всего используются с мощной компьютерной техникой, потому что человеческий мозг не в состоянии обрабатывать такие массивы информации.
Методы поэтапной структуризации направлены на то, чтобы найти логические взаимосвязи, а морфологические методы не ставят перед собой задачу найти логический вывод, но они проводят тщательный комбинаторный анализ и сортируют информацию более тщательно и глубоко.
Однако эффективность работы заключается в том, чтобы использовать оба эти метода. Структурирование цифровой информации требует комплексного подхода. Именно по этой причине важно не только использовать самые доступные методы, но и прибегать к планированию, экспериментам и другим методам отраслевой специфики.
Технология структурирования информации во многом зависит от того, насколько детально должна быть проделана работа. Так, при структурировании в первую очередь учитывается специфика отрасли.
Анализ и структурирование информации очень выгодно рассматривать в разрезе семиотики. Это подход, который интерпретирует любое способы представления информации как одну из разновидностей текста. Использование знаковой системы позволяет максимально упростить и облегчить понимание информации. Так, при графическом представлении мы используем целый ряд методов, которые позволяют переходить от тональности к контрасту, от насыщенности к яркости и так далее. Все это позволяет упрощать распознавание данных и транслировать их для других знаковых систем. Но поскольку графические модели несколько ограничены, то извлечь из них информацию чаще всего проще с использованием модели интерпретации.
Структурирование информации в медиатеке ПК и серверов
Мы подробно рассмотрели вопросы структурирования, но не затронули вопрос в разрезе цифровой информации. В современном мире информационные компьютерные технологии внедряются во все сферы жизни. Поэтому игнорировать их просто невозможно. Последнее время большое развитие получили информационные медиатеки, которые используются в школах, высших учебных учреждениях, техникумах. Медиатеки ПК и серверов объединяют в себе методические учебные пособия, звукозаписи, фонды книг, видеофайлы, компьютерные презентации, а также техническое обеспечение, необходимое для выведения всей перечисленной информации. На сегодняшний день каждое образовательное учреждение создает свою медиатеку, регулярно пополняемую новой информацией, зафиксированной на различных носителях. Это позволяет развивать самостоятельную работу учащихся с телекоммуникациями и электронными каталогами. Функции, которые выполняет медиатека, следующие:
- Структурирование информации с использованием информационных моделей для хранения дипломных работ учащихся рефератов, презентаций и так далее.
- Полная автоматизация работы с библиотекой.
- Обновление и хранение учебных общеобразовательных материалов в электронной форме.
- Хранение справочно-информационных пособий.
- Неограниченный доступ к сетевым ресурсам и электронным библиотекам.
- Хранение и просмотр фото- и видеофайлов образовательного учреждения.
- Поиск необходимой информации по запросу.
- Оперативная работа с любыми источниками информации.
Важную роль играет структурирование хранения информации. Для этого учреждениям необходимо владеть мощными серверами, которые бы гарантировали невредимость и сохранность данных. Именно поэтому к вопросу необходимо подходить грамотно и профессионально, ведь в случае ошибки упущенные данные можно не вернуть.
Структурирование информации в медиатеке ПК требует наличия мощного компьютерного оборудования, включая мобильные устройства, ноутбуки, зарядные устройство и так далее. Только высококачественное оборудование позволит обеспечивать полноценную работу с материалами одновременно для всех пользователей. Также очень важно завести центральный сервер, на котором будут храниться данные. Чаще всего сервера устанавливаются в библиотеках. Установка беспроводной сети позволяет каждому преподавателю или учащемуся получать доступ ко всем материалам с ноутбука, не выходя из дома.
Структурирование информации в базах данных
База данных – это некая совокупность данных, которые совместно используются персоналом предприятия, региона, учащимися вуза и так далее. Задача баз данных состоит в том, чтобы можно было хранить большой объем информации и предоставлять их по первому запросу.
Правильно спроектированная база данных полностью исключает избыточность данных, благодаря чему риск хранения противоречивой информации сводится к минимуму. Исходя из этого, можно сказать, что создание баз данных в современном мире преследует две основные цели – это повышение надежности данных и понижении их избыточности.
Жизненный цикл программного продукта состоит из стадий проектирования, реализации и эксплуатации, но основной и ключевой является стадия проектирования. От того, насколько грамотно она продумана, насколько четко определены связи между всеми элементами, зависит информационная насыщенность и общая производительность.
Правильно спроектированная база данных должна:
- Гарантировать целостность данных.
- Исследовать, находить и удалять противоречивости.
- Обеспечивать легкое восприятие.
- Позволять пользователю структурировать информацию и вносить новые данные.
- Удовлетворять требования производительности.
Перед проектированием базы данных проводят тщательный анализ требований пользователей к будущему программному продукту. При этом от программиста требуется знание основных правил и ограничивающих факторов для того, чтобы грамотно выстроить логические взаимосвязи между запросами. Очень важно правильно проработать поисковой атрибут для того, чтобы пользователи могли по несортированным ключевым словам находить желаемую информацию. Также надо помнить, что чем больший объем информации хранит в себе база данных, тем важнее для нее вопрос производительности, ведь именно при максимальных нагрузках становятся видны все недочеты.
Роль информации в современном мире
Способы структурирования информации, которые мы рассмотрели, направлены на то, чтобы максимально облегчить доступ к данным, хранение их в цифровом или материальном виде. Все они в своей сущности довольно простые, но для их понимания необходимо осознание того, что информация – это лишь абстрактное понятие.
Ее сложно измерить, потрогать или увидеть в той или иной конкретной форме. С точки зрения структурирования информации любой объект представляет собой лишь набор определенных данных и характеристик, которые мы можем представить и разбить на какие-то составные части.
При этом понимание ключевых отличий объектов базируется на том, что мы сравниваем его значения с нормой или с тем объектом, который мы используем для сравнения. Для того чтобы научиться быстро и эффективно структурировать информацию, важно понимать, что она представляет собой всего лишь набор определенных характеристик, свойств и параметров. Научившись правильно с ними обращаться и классифицировать, можно решить множество бытовых и профессиональных задач.
Также важно помнить, что информация всегда может быть записана, изображена или представлена другим способом. Говоря иными словами, если вы чего-то не понимаете, необходимо настолько разбить эту тему на подробные элементы и вникнуть в их суть, чтобы не осталось ничего, чего нельзя было бы объяснить простым языком.
В бытовом плане большинство довольно легко решает такие задачи, изобретая интеллектуальные карты и используя особенности своего мозга, открытые учеными. Но в профессиональном плане структурирование информации до сих пор остается довольно сложной задачей, поскольку ее количество ежедневно и ежеминутно растет.
По сути, вся эволюция человека – это процесс накопления знаний. Но при этом, чтобы эффективно работать, необходимо понять основные принципы структурирования информации, о которых мы тоже говорили ранее. Их не так много. Однако понимание — это ключ к обработке огромных массивов информации и их запоминанию.
50 инструментов для анализа и визуализации данных
50 новых инструментов, демократизирующих процесс анализа и визуализации данных от Леонардо Мерфи.
Подобно тому как ранее мы стали свидетелями перехода на платформы сбора данных, работающие по принципу «сделай сам», теперь мы также можем наблюдать за развитием целого нового класса инструментов для самостоятельного изучения и визуализации данных. Это необязательно замена SPSS, SAS, R и других традиционных аналитических наборов программ – последние представляют собой системы корпоративного уровня и зачастую по-прежнему необходимы для проведения более сложного и продвинутого статистического анализа. Однако у новичков довольно много преимуществ перед существующими инструментами: они менее дорогие (во многих случаях бесплатные), более гибкие, проще в использовании и построены с учетом потребностей самых разных пользователей. Сегодня можно найти множество инструментов, которые могут помочь даже самому неопытному пользователю быстро освоиться и начать работать со сложными видами анализа, создавая превосходные визуализации на основе различных типов данных.
Демократизация процесса анализа данных идет полным ходом.
Конечно, большой выбор различных программ, доступных аналитикам и исследователям, существовал всегда, так что само по себе расширение их арсенала не является революционным событием. К примеру, если говорить только об отрасли маркетинговых исследований, за прошедшие годы платформы сбора данных на основе опросов интегрировали в свои предложения достаточно продвинутые инструменты анализа данных, однако они, в большинстве случаев, ограничиваются сбором данных в рамках соответствующей системы и не особенно хорошо подходят для синтеза массивов внешних данных. Даже несмотря на тот факт, что зачастую они способны на гораздо большее, обычно их использование ограничено управлением полевыми исследованиями и некоторыми возможностями клиентского доступа к данным на ранних этапах исследования и не включает в себя полностью интегрированного процесса подготовки отчетов по полученным данным.
С начала моей работы в области маркетинговых исследований в конце прошлого века стандартный рабочий процесс обработки данных состоял, в основном, из следующих действий: экспорт данных в разделенном формате в SPSS, их очистка с помощью этого приложения, экспорт в WinCross или другое приложение для сведения данных в таблицы, а затем создание массивов перекрестных табличных данных и документов в формате Excel на основе полученных таблиц. Программное обеспечение типа e-Tabs и MarketSight позволяло упростить некоторые из этих процессов и, конечно, в ряде организаций возможности систем сбора данных использовали в большем объеме или же разрабатывали собственные решения с применением макросов, однако большинство представителей этой отрасли ограничивались стандартизованными технологическими операциями.
Следует отметить, что в большинстве случаев от специалистов по анализу рынка требовалось лишь проанализировать массивы дискретных данных и подготовить разнообразные графические иллюстрации по основным полученным результатам. Однако в начале 2000-х эта ситуация начала меняться с появлением таких инструментальных панелей, как Xcelsius, Crystal Reports, Dundas Charts и многих других, поскольку мы начали осознавать потребности клиентов в новых способах работы с полученными данными. Однако зачастую эти платформы по-прежнему работали в рамках принятого поэтапного процесса, включавшего в себя сбор данных в одной системе, их экспорт в статистическое приложение для очищения и анализа и последующий экспорт в базу данных на SQL или даже в крупноформатные таблицы типа Excel, чтобы с ними можно было работать с использованием этих инструментальных панелей. Такая система работы была громоздкой и часто приводила к сбоям. Немногие поставщики услуг в области маркетингового анализа начали работать с системами таких инструментальных панелей и были довольны сложившейся ситуацией, что позволило специалистам в области информационных технологий и бизнес-анализа возглавить революцию в сфере визуализации данных на ее ранних стадиях с использованием этих и подобных им инструментов.
Ввиду того, что интерес клиентов не угас (а, по сути, даже вырос в плане объемов и четкости представления данных), технические специалисты сделали то, что они делают всегда: создали новые, более эффективные модели, которые разрушили существовавшую парадигму. Во всех областях – от синтеза до визуализации – и для всех возможных типов данных появились инструменты, которые невероятно упростили процесс использования данных для эффективного анализа. Большинство этих инструментов не требуют навыков программирования или даже какой-либо серьезной подготовки – все процессы управляются методом «указания и щелчка», а большая часть наиболее сложной работы проходит без участия пользователя.
Я экспериментировал с некоторыми из этих платформ, наиболее подходящими для традиционных методов исследования, и далее в этой статье я расскажу вам о нескольких самых любимых, а также изложу свои мысли об их применимости в области маркетинговых исследований. Эту статью ни в коем случае нельзя считать полным перечнем существующих возможностей или даже подробным отчетом по ним, это скорее краткое введение в работу с некоторыми инструментами, о которых вы, возможно, еще не слышали, которое было создано именно для того, чтобы вы могли с ними познакомиться.
Также следует упомянуть, что в данной статье не рассматривались платформы Infotools, Research Reporter и Tableau так как я не пользовался ими лично, хотя и слышал только хорошие отзывы пользователей в их адрес. В частности, Infotools, похоже, стремится расширить существующие границы и сделать процесс анализа и визуализации данных для исследований более легким и эффективным для всех типов проектов в этой области.
Именно эти и названные ниже компании помогают изменить процедуру обнаружения полезных инсайтов, делая процесс анализа данных более доступным для тех из нас (включая меня самого), кто не являются дипломированными специалистами по статистике или анализу данных.
OfficeReports
Программа OfficeReports – это настоящее сокровище. Она помогает решить давнюю проблему многих специалистов по маркетинговым исследованиям, упрощая процесс перевода данных из программ обработки статистических показателей напрямую в основное приложение для подготовки отчетов – Microsoft Office. Она не изобретает велосипед заново, но значительно совершенствует его. Мы можем сколько угодно горевать по поводу своей зависимости от PowerPoint и Excel, и все же именно они являются стандартным коммерческим программным обеспечением всего мира. Сотрудники Office Reports прекрасно это понимают и потому разработали программу, которая выглядит, ощущается и функционирует, как дополнение к Office, и справляется со всем этим очень и очень хорошо.
OfficeReports позволяет, ни больше ни меньше, превратить Microsoft Office в полноценное приложение для проведения полного анализа данных и подготовки отчета по ним для исследований. OfficeReports добавляет кнопку «Меню OfficeReports» на панель PowerPoint и Word. Через меню OfficeReports вы можете вставить массив данных в документ или презентацию и затем с легкостью работать с этими данными, создавать таблицы и графики. И все это прямо в Microsoft Office.
Посмотрите этот краткий ознакомительный видеоролик:
Second Prism
Second Prism входит в группу компаний Survey Analytics. Это облегченная версия базы данных для Mobile Adapter, которая позволяет быстро и безопасно публиковать динамично меняющиеся отчеты на мобильных устройствах. Ее графическое представление отличается четкостью и интуитивной понятностью, а вся система в целом разработана для предоставления возможности поделиться полученной информацией с другими членами рабочей команды или третьими лицами в социальных сервисах. Если обеспечение доступа к интерактивным диаграммам и графикам с мобильных устройств является приоритетной задачей, Second Prism – это надежная платформа, позволяющая реализовать эту возможность удобным для пользователя способом.
Посмотрите видеоролик с кратким обзором продукта, приведенный ниже.
Databoard
Databoard Databoard – новинка мира удобных для использования инструментов работы с данными от Google. Это простое, интуитивно понятное и бесплатное приложение, которое служит наглядной иллюстрацией новой парадигмы открытых данных. На Gigaom несколько недель назад появился обзор, посвященный этой программе, и вот что в нем сказано:
Новая программа от Google Databoard так хороша не из-за статистических данных, полученных компанией в рамках различных исследований в индустрии мобильных устройств, а скорее потому, что она бесплатна, симпатична и с ней легко начать работать. Она, конечно, не сможет в обозримом будущем заменить собой целые аналитические или исследовательские компании, однако если бы я сам занимался бизнесом, в котором за отчеты по маркетинговым исследованиям выставляют счета на сотни тысяч долларов, то я бы не стал относиться к Databoard чересчур легкомысленно.
В двух словах новый сервис можно описать так: сотрудники Google провели множество исследований, посвященных тому, как люди пользуются мобильными устройствами, и теперь создали сервис, с помощью которого вы легко можете получить доступ к основным резутатам этих исследований, а затем поделиться ими с другими людьми или же преобразовать их в инфографику. Вы также можете просто скачать отчеты по этим исследованиям целиком. Это невероятно простая и, теоретически, невероятно полезная программа.
Сейчас я пытаюсь понять, какими могут быть следующие шаги компании по развитию Databoard. Если они будут включать в себя предоставление пользователям возможности загружать собственные массивы данных или привязывать их к данным потребительских исследований Google, тогда я, пожалуй, соглашусь с Gigaom в том, что это – первый звоночек для всей отрасли маркетинговых исследований. В данный момент это превосходный ресурс, позволяющий изучить вторичные данные и создать на их основе некоторую базовую инфорграфику, а, кроме того, это вполне понятный указатель возможных будущих перемен.
DataMarket
DataMarket – это гибридное решение, выполняющее сразу несколько функций:
- Это портал открытых данных, предоставляющий возможность просмотра и анализа тысяч публично доступных массивов данных. Необычен он тем, что вы можете самостоятельно отбирать переменные из множества отдельных массивов и комбинировать их или же создавать перекрестные сводки данных. Хотите установить взаимосвязь между уровнем безработицы в Ирландии и индексом Доу-Джонса в любой определенный день и проанализировать его с точки зрения стандартных демографических показателей? Data Market позволит вам реализовать это на практике.
- Вы можете официально оформить платформу как собственный концентратор информации. Загрузите свои данные и предоставьте желающим возможность просматривать и анализировать их. И, опять-таки, здесь реализована возможность получения мгновенного доступа к множеству переменных из различных массивов данных и проведения довольно сложного анализа – и все это делается по одному щелчку мыши.
- Систематизируйте и находите нужные вам данные. Поисковый сервис программы Datamarket обладает превосходной функциональностью и позволяет систематизировать данные множеством различных способов в соответствии с вашими потребностями. Это очень гибкая система классификации, которая создает вашу библиотеку прямо в процессе работы с данными.
Вот ознакомительный видеоролик программы.
Q Research Software
Я являюсь поклонником Q Research Software вот уже несколько лет. Эта компания стала нашим партнером по обработке и доставке данных на нескольких последних этапах работы по проекту исследований GRIT благодаря надежности своей платформы. В отличие от других упомянутых решений, это полноценная альтернатива SPSS, SAS и другим системам. Разработанная австралийской фирмой Numbers, Inc. программа Q предлагает надежный и простой для понимания интерфейс, который отвечает требованиям как новичков, так и продвинутых пользователей, включая в себя такие функции как анализ выбора, многовариантный анализ, прогнозное моделирование и интерактивная панель инструментов для создания диаграмм и работы с данными, позволяющая визуализировать полученные результаты и подготавливать по ним соответствующие отчеты.
Одной из ее характеристик, которая мне очень нравится, является возможность отбирать и комбинировать переменные из любого массива данных, загруженного мной для проведения дополнительного анализа. Также впечатляет функция, позволяющая с легкостью соединить или перекодировать данные прямо в процессе работы. Меня удивляет тот факт, что компания IBM или какой-либо из ее конкурентов до сих пор не выкупили Q – это по-настоящему хорошо проработанная аналитическая система, и я подозреваю, что в самое ближайшее время найдется кто-то, кто приобретет ее, чтобы вывести на следующий уровень.
Следующий видеоролик поможет вам получить представление об этом удивительном инструменте:
Statwing
Statwing – одна из компаний, которые были приглашены в качестве участников конкурса Insight Innovation Challenge, прошедшего в IIeX Philadelphia в июне. Еще до презентации своего проекта она показалась интересной многим участникам, а уже после нее этот интерес возрастал в геометрической прогрессии. И нетрудно понять, почему. По их собственным словам, предложенная ими программа позволяет: Проанализировать статистические взаимосвязи без специализированных знаний. Визуализировать имеющиеся данные одним щелчком мыши. Благодаря Statwing процесс работы с данными становится интуитивно понятным и прекрасным.
И именно это она обеспечивает. У нее невероятно простой пользовательский интерфейс, за которым скрыты очень сложные рабочие модели. Она подбирает подходящие статистические тесты автоматически, с учетом выбросов или других проблем имеющихся массивов данных. Эта программа представляет результаты работы четко, в соответствующем визуальном оформлении и интерактивном формате. Неудивительно, что на компанию обратили самое пристальное внимание представители технической отрасли и бизнес-аналитики – она действительно помогает даже начинающим пользователям проводить сложные виды анализа и создавать эффектные визуализации.
И, наконец, давайте взглянем на Dapresy. Dapresy широко используется многими фирмами, занимающимися маркетинговыми исследованиями, благодаря имеющемуся инструментарию и функциям подготовки отчетов (с чем она очень хорошо справляется), но от прочих ее отличает возможность интеграции механизма создания инфографики и дизайнерской студии, что помогает пользователям быстро и без лишних затрат создать собственную графическую библиотеку. Вот чуть более подробное описание с официального сайта проекта:
Dapresy Pro создает веб-порталы для загрузки динамичных онлайн-презентаций и отчетов, своевременно предоставляя четкие, применимые на практике результаты анализа данных, полученных в ходе исследований, и другой коммерческой информации, поступившей с рынков, от пользователей и потребителей.
Помимо возможности создания превосходных панелей инструментов для работы с инфографикой, система предлагает полностью интегрированные модули для обработки, статистического учета и анализа данных, построения таблиц с перекрестными ссылками, а также составления диаграмм и автоматического обновления данных.
Можно найти множество примеров результатов работы системы в разделе Ideabox, и как пользователь я могу сказать, что создавать похожие высококачественные визуализации и интерактивные панели довольно легко. Все это произвело на меня столь сильное впечатление, что я планирую начать использовать некоторые возможности Dapresy в GRIT уже на следующем этапе работы.
Это лишь несколько из недавно вышедших программ, которые я изучил лично. В действительности их намного больше, особенно если углубиться в обширную зону бизнес-аналитики и больших данных. Такие инструменты как DataHero, Wolfram Alpha, BigML, LavaStorm и ManyEyes все чаще вытесняют традиционные статистические программы, используемые исследователями. Конечно, некоторые из них далеки от простоты во всех смыслах этого слова, однако многие были разработаны с тем, чтобы серьезно облегчить задачу анализа данных, полученных из множества различных источников. Эпоха, в которую статистики и аналитики были узкоспециализированными экспертами, стремительно подходит к концу, так как эти инструменты позволяют любому желающему с легкостью выполнять ту же работу. И все же навыки профессионалов по работе с данными останутся востребованными, хотя уже, скорее, в сфере развития информационных технологий, чем в аналитике, так как в игру вступает все больше и больше инструментов, позволяющих автоматизировать этот процесс для любого пользователя.
И чтобы сделать эту статью действительно полезной для вас, я хочу познакомить вас с восхитительной интерактивной таблицей, созданной в Computerworld, в которой представлены разнообразные совершенно бесплатные инструменты: Инструменты визуализации и анализа данных. Для удобства я скопировал саму таблицу – она приведена ниже – убрав из нее интерактивные элементы.
| Инструмент | Категория | Многоцелевая визуализация | Построение схем | Платформа | Уровень квалификации | Хранение или обработка данных |
Возможность публикации в Интернете |
| Data Wrangler | Очистка данных | Нет | Нет | Браузер | 2 | Внешний сервер | Нет |
| OpenRefine (formerly Google Refine) | Очистка данных | Нет | Нет | Браузер | 2 | Локально | Нет |
| R Project | Статистический анализ | Да | С плагином | Linux, Mac OS X, Unix, Windows XP или выше | 4 | Локально | Нет |
| Google Fusion Tables | Визуализация данных | Да | Да | Браузер | 1 | Внешний сервер | Да |
| Impure | Визуализация данных | Да | Нет | Браузер | 3 | Различные варианты | Да |
| Many Eyes |
Визуализация данных |
Да | Органичено | Браузер | 1 | Общедоступный внешний сервер | Да |
| Tableau Public | Визуализация данных | Да | Да | Windows | 3 | Общедоступный внешний сервер | Да |
| VIDI |
Визуализация данных |
Да | Да | Браузер | 1 | Внешний сервер | Да |
| Zoho Reports | Визуализация данных | Да |
Нет |
Браузер | 2 | Внешний сервер | Да |
| Choosel | Интегрированная среда | Да | Да |
Chrome, Firefox, Safari |
4 | Локальный или внешний сервер | Нет |
| Exhibit | Библиотека | Да | Да | Редактор кода и браузер | 4 | Локальный или внешний сервер | Да |
| Google Chart Tools | Библиотека и визуализация | Да | Да | Редактор кода и браузер | 2 | Локальный или внешний сервер | Да |
| JavaScript InfoVis Toolkit | Библиотека | Да | Нет | Редактор кода и браузер | 4 | Локальный или внешний сервер | Да |
| D3 | Библиотека | Да | Да | Редактор кода и браузер | 4 | Локальный или внешний сервер | Да |
| Quantum GIS (QGIS) | ГИС | Нет | Да | Linux, Unix, Mac OS X, Windows | 4 | Локально | С плагином |
| OpenHeatMap | ГИС | Нет | Да | Браузер | 1 | Внешний сервер | Да |
| OpenLayers | ГИС | Нет | Да | Редактор кода и браузер | 4 | Локальный или внешний сервер | Да |
| OpenStreetMap | ГИС | Нет | Да | Браузер | 3 | Локальный или внешний сервер | Да |
| TimeFlow |
Анализ временных рядов |
Нет | Нет | Компьютер с Java | 1 |
Локально |
Нет |
| IBM Word-Cloud Generator | Облака слов | Нет | Нет |
Компьютер с Java |
2 | Локально | В Виде изображения |
| Gephi | Сетевой анализ | Нет | Нет | Компьютер с Java | 4 | Локально | В Виде изображения |
| NodeXL | Сетевой анализ | Нет | Нет | Excel 2007 and 2010 on Windows | 4 | Локально |
В Виде изображения |
| CSVKit | Анализ CSV-файлов | Нет | Нет | Linux, Mac OS X or Linux with Python installed | 3 | Локально | Нет |
| DataTables | Создание таблиц с возможностью сортировки и поиска | Нет | Нет | Редактор кода и браузер | 3 | Локальный или внешний сервер | Да |
| FreeDive | Создание таблиц с возможностью сортировки и поиска | Нет | Нет | Браузер | 2 | Внешний сервер | Да |
|
Highcharts* |
Библиотека | Да | Нет | Редактор кода и браузер | 3 | Локальный или внешний сервер | Да |
| Mr. Data Converter | Преобразование данных | Нет | Нет | Браузер | 1 | Локальный или внешний сервер | Нет |
| Panda Project | Создание таблиц с возможностью поиска | Нет | Нет | Browser с Amazon EC2 или Ubuntu Linux | 2 | Локальный или внешний сервер | Нет |
|
PowerPivot** |
Анализ и построение схем | Да | Нет | Excel 2010/2013 | 3 | Локально | Нет |
| Weave | Визуализация данных | Да | Да | Браузеры с Flash | 4 | Локальный или внешний сервер | Да |
| Statwing | Визуализация данных | Да | Нет | Браузер | 1 | Внешний сервер | Нет |
| Infogr.am | Визуализация данных | Да | Ограничено | Браузер | 1 |
Внешний сервер |
Да |
| Datawrapper | Визуализация данных | Да | Нет | Браузер | 1 | Локальный или внешний сервер | Да |
|
Cascading Tree Sheets |
Библиотека | Да | Да | Браузер | 1 | Локальный или внешний сервер | Да |
| Dataset | Библиотека | Нет | Нет | Браузер | 4 | Локальный или внешний сервер | Да |
|
Leaflet |
Библиотека | Нет | Да | Браузер | 4 | Локальный или внешний сервер | Да |
| Searchable Fusion Table Map Template | Библиотека | Нет | Да | Браузер | 3 | Локальный или внешний сервер | Да |
| Tabletop | Библиотека | Нет | Нет | Браузер | 3 | Локальный или внешний сервер | Да |
|
Data Explorer** |
Преобразование данных | Нет | Нет | Excel 2010/2013 | 2 | Локально | Нет |
|
eSpatial |
ГИС/картографирование | Нет | Да | Браузер | 2 | Внешние ресурсы | Да |
|
Jolicharts |
Визуализация данных | Да | Да | Браузер | 1 |
Внешний сервер |
Да |
| Silk | Визуализация данных | Да | Да | Браузер | 1 | Внешний сервер | Да |
| Chartbuilder | Визуализация данных | Да | Нет | Браузер | 1 | Локально | Да |
|
MicroStrategy Analytics Desktop |
Приложение для ПК | Да | Нет | Windows | 3 | Локально | Да |
|
Plotly |
Визуализация данных | Да | Нет | Браузер | 1 | Внешний сервер | Да |
| Vida.io | Визуализация данных | Да | Да | Браузер | 1 | Внешний сервер | Да |
*Программа Highcharts бесплатна для некоммерческого использования, а также распространяется по цене $80 в большинстве случаев лицензирования для использования на одном сайте.
**В то время как встраиваемые программы бесплатны, пакет Excel (который необходим для их работы) таковым не является.
Надеюсь, вы протестируете хотя бы некоторые из представленных в этом списке программ лично. Существует гораздо больше доступных специалистам по маркетинговым исследованиям инструментов, чем SPSS, WinCross, Excel и PowerPoint, и многими из них легче пользоваться. Изучите их возможности и найдите решения, которые могут помочь вам сделать процесс анализа и визуализации данных дешевле, проще и эффективнее.
Основные сведения о базах данных
Эта статья содержит краткие сведения о базах данных: что это, чем они могут быть полезны, каковы функции их отдельных элементов. Здесь используется терминология, свойственная Microsoft Access, однако описываемые понятия применимы по отношению к любым базам данных.
В этой статье:
Что представляет собой база данных?
База данных — это инструмент для сбора и у организатора сведений. В базах данных могут храниться сведения о товарах, товарах, заказах и других данных. Многие базы данных начинаются с списка в word-processing program или spreadsheet. По мере роста списка в данных появляются избыточные и несоответствия. Данные становится трудно понять в форме списка, и существует ограниченный способ поиска или вывода подмног данных для проверки. Когда эти проблемы начнут появляться, лучше перенести данные в базу данных, созданную системой управления базами данных (СУБД), такой как Access.
Компьютерная база данных — это хранилище объектов. В одной базе данных может быть больше одной таблицы. Например, система отслеживания складских запасов, в которой используются три таблицы, — это не три базы данных, а одна. В базе данных Access (если ее специально не настраивали для работы с данными или кодом, принадлежащими другому источнику) все таблицы хранятся в одном файле вместе с другими объектами, такими как формы, отчеты, макросы и модули. Для файлов баз данных, созданных в формате Access 2007 (который также используется в Access 2016, Access 2013 и Access 2010), используется расширение ACCDB, а для баз данных, созданных в более ранних версиях Access, — MDB. С помощью Access 2016, Access 2013, Access 2010 и Access 2007 можно создавать файлы в форматах более ранних версий приложения (например, Access 2000 и Access 2002–2003).
Использование Access позволяет:
-
добавлять новую информацию в базу данных, например новый артикул складских запасов;
-
изменять информацию, уже находящуюся в базе, например перемещать артикул;
-
удалять информацию, например если артикул был продан или утилизирован;
-
упорядочивать и просматривать данные различными способами;
-
обмениваться данными с другими людьми с помощью отчетов, сообщений электронной почты, внутренней сети или Интернета.
Элементы базы данных Access
Ниже приведены краткие описания элементов стандартной базы данных Access.
Таблицы
Таблица базы данных похожа на электронную таблицу — и там, и там информация расположена в строках и столбцах. Поэтому импортировать электронную таблицу в таблицу базы данных обычно довольно легко. Основное различие заключается в том, как данные структурированы.
Чтобы база данных была как можно более гибкой и чтобы в ней не появлялось излишней информации, данные должны быть структурированы в виде таблиц. Например, если речь идет о таблице с информацией о сотрудниках компании, больше одного раза вводить данные об одном и том же сотруднике не нужно. Данные о товарах должны храниться в отдельной таблице, как и данные о филиалах компании. Этот процесс называется нормализацией.
Строки в таблице называются записями. В записи содержатся блоки информации. Каждая запись состоит по крайней мере из одного поля. Поля соответствуют столбцам в таблице. Например, в таблице под названием «Сотрудники» в каждой записи находится информация об одном сотруднике, а в каждом поле — отдельная категория информации, например имя, фамилия, адрес и т. д. Поля выделяются под определенные типы данных, например текстовые, цифровые или иные данные.
Еще один способ описания записей и полей — визуализация старого стиля каталога карток библиотеки. Каждая карточка в карточке соответствует записи в базе данных. Каждый фрагмент сведений на отдельной карточке (автор, заголовок и так далее) соответствует полю в базе данных.
Дополнительные сведения о таблицах см. в статье Общие сведения о таблицах.
Формы
С помощью форм создается пользовательский интерфейс для ввода и редактирования данных. Формы часто содержат кнопки команд и другие элементы управления, предназначенные для выполнения различных функций. Можно создать базу данных, не используя формы, если просто отредактировать уже имеющуюся информацию в таблицах Access. Тем не менее, большинство пользователей предпочитает использовать формы для просмотра, ввода и редактирования информации в таблицах.
С помощью кнопок команд задаются данные, которые должны появляться в форме, открываются прочие формы и отчеты и выполняется ряд других задач. Например, есть «Форма клиента», в которой вы работаете с данными о клиентах. И в ней может быть кнопка, нажатием которой открывается форма заказа, с помощью которой вы вносите информацию о заказе, сделанном определенным клиентом.
Формы также дают возможность контролировать взаимодействие пользователей с информацией базы данных. Например, можно создать форму, в которой отображаются только определенные поля и с помощью которой можно выполнять только ограниченное число операций. Таким образом обеспечивается защита и корректный ввод данных.
Дополнительные сведения о формах см. в статье Формы.
Отчеты
Отчеты используются для форматирования, сведения и показа данных. Обычно отчет позволяет найти ответ на определенный вопрос, например «Какую прибыль в этом году принесли нам наши клиенты?» или «В каких городах живут наши клиенты?» Отчеты можно форматировать таким образом, чтобы информация отображалась в наиболее читабельном виде.
Отчет можно сформировать в любое время, и в нем всегда будет отображена текущая информация базы данных. Отчеты обычно форматируются таким образом, чтобы их можно было распечатать, но их также можно просматривать на экране, экспортировать в другие программы или вкладывать в сообщения электронной почты.
Дополнительные сведения об отчетах см. в статье «Обзор отчетов в Access».
Запросы
Запросы могут выполнять множество функций в базе данных. Одна из их основных функций — находить информацию в таблицах. Нужная информация обычно содержится в нескольких таблицах, но, если использовать запросы, ее можно просматривать в одной. Кроме того, запросы дают возможность фильтровать данные (для этого задаются критерии поиска), чтобы отображались только нужные записи.
Используются и так называемые «обновляемые» запросы, которые дают возможность редактировать данные, найденные в основных таблицах. При работе с обновляемым запросом помните, что правки вносятся в основные таблицы, а не только в таблицу запроса.
У запросов два основных вида: запросы на выборки и запросы на выполнение действий. Запрос на выборки просто извлекает данные и делает их доступными для использования. Вы можете просмотреть результаты запроса на экране, распечатать его или скопировать в буфер обмена. Вы также можете использовать выходные данные запроса в качестве источника записей для формы или отчета.
Запрос на изменение, как следует из названия, выполняет задачу с данными. С помощью запросов на изменения можно создавать новые таблицы, добавлять данные в существующие таблицы, обновлять или удалять данные.
Дополнительные сведения о запросах см. в статье Знакомство с запросами.
Макросы
Макросы в Access — это нечто вроде упрощенного языка программирования, с помощью которого можно сделать базу данных более функциональной. Например, если к кнопке команды в форме добавить макрос, то он будет запускаться всякий раз при нажатии этой кнопки. Макросы состоят из команд, с помощью которых выполняются определенные задачи: открываются отчеты, выполняются запросы, закрывается база данных и т. д. Используя макросы, можно автоматизировать большинство операций, которые в базе данных вы делаете вручную, и, таким образом, значительно сэкономить время.
Дополнительные сведения о макросах см. в статье Общие сведения о программировании в Access.
Модули
Подобно макросам, модули — это объекты, с помощью которых базу данных можно сделать более функциональной. Но если макросы в Access составляются путем выбора из списка макрокоманд, модули создаются на языке Visual Basic для приложений (VBA). Модули представляют собой наборы описаний, инструкций и процедур. Существуют модули класса и стандартные модули. Модули класса связаны с конкретными формами или отчетами и обычно включают в себя процедуры, которые работают только с этими формами или отчетами. В стандартных модулях содержатся общие процедуры, не связанные ни с каким объектом. Стандартные модули, в отличие от модулей класса, перечисляются в списке Модули в области навигации.
Дополнительные сведения о модулях см. в статье Общие сведения о программировании в Access.
К началу страницы
способы и виды автоматизации сборки
Структурирование информации – разбираемся в термине
О том, что такое структурирование, знают многие. «Разложить по полочкам» – значит «структурировать». Структурирование информации – это разделение её по отдельным, схожим критериям на группы, а также выстраивание связей логических цепочек между полученными группами. Иными словами, структурировать информацию означает создать некий визуальный скелет, с помощью которого будет легко запомнить ту или иную информацию. Как нетрудно догадаться, нужно оно для того, чтобы проще, легче было её запомнить. Причём информация может являться абсолютно любого типа: текст, числа, учебный материал, развлекательный.
Любая информация нуждается в структурировании, если вы хотите быстро для себя её зафиксировать. Как это делать, читаем далее.
Принципы структурирования информации
В основе данного понятия – её упрощение. Иными словами, нам нужно данный сложный массив логических связей, цепочек разобрать на простые элементы. Важно знать два принципа – на них строится всё упрощение информации:
- Принцип первый: всю имеющуюся информацию необходимо разделить на группы, подгруппы в соответствии с отдельно взятыми критериями. Здесь всё просто: берём какой-либо критерий, признак, на котором построена информация – например, раздел «Числительные» в иностранных языках, после чего подгоняем всю имеющуюся информацию под написанный критерий – запоминаем только иностранные числительные.
- Принцип второй: группы и подгруппы должны быть тесно связаны логическими цепочками, ассоциативными рядами или же выстроены в соответствии с определёнными правилами: по степени важности, по времени, форме. Те же иностранные числительные можно «связать» похожим звучанием, правилами построения их форм.
Методы и виды структурирования информации
Отталкиваясь от указанных принципов, приведём самые популярные и зарекомендовавшие себя методы получения структурированной информации.
«Карта памяти» – метод Бьюзена
Метод довольно прост. Он заключается в построении блок-схемы – в ней будет наглядно изображена вся информация. В основе этого алгоритма лежит автоматизация сборки.
Чтобы изобразить блок-схему, необходимо взять лист бумаги (ватман), ручку. При желании – для большей наглядности – стоит взять ещё цветные карандаши, фломастеры. В центре листа обозначьте название материала, который необходимо запомнить. Если это учебник «История Древнего Египта», так и пишите. «Принцип работы вариаторной коробки в автомобиле» или «Как работает программа 1С» – пишите. Советуется слова заменить символами или картинками, которые точно будут передавать суть темы. Ту же вариаторную коробку наглядно изобразите на бумаге, а 1С – просто обозначить символом программы. При желании можно вырезать, наклеить картинки – как угодно. Лишь бы вам было проще запомнить. Далее, нужно для выбранной темы построить ряд ассоциативных рядов. История Древнего мира – это цепочки «Периоды», «Народы», «Войны». В каждом блоке перечисляем ключевые моменты. И так далее по такому принципу. За счёт наглядности, разбивания материала на блоки запоминание информации произойдёт довольно быстро.
«Римская комната» метод Цицерона
Данный метод существует ещё со времён римского философа Цицерона, поэтому в его эффективности сомневаться не стоит. Суть метода в том, что материал разбивается на отдельные блоки, а затем мысленно расставляется в знакомой вам комнате – скажем, в вашей кухне.
Важно! Все блоки надо расставляться в строго определённом порядке.
Как только вы «расставите» блоки по комнате, в вашей памяти зафиксируется простая цепочка информации, которую вы легко запомните. И теперь, чтобы обратиться к информации, вам достаточно будет вспомнить вашу кухню. Кстати, под кухней необязательно выбирать комнату: используйте улицу, парк, даже шкаф. Главное, чтобы вы чётко понимали, помнили структуру помещения, объекта.
«7плюс/минус2»: метод Миллера
Этот интересный метод основан на способности человека запоминать 9 двоичных чисел, 8 – десятичных, 7 букв, 5 слов, причём это кратковременная память. Таким образом, данными способом получается группу из семи плюс/минус два элементов – её мы можем использовать для создания групп и подгрупп. Однако данный метод чаще применяется для тренировки памяти, но в структурировании информации его тоже частенько используют.
Отдельно стоит поговорить про эффекты запоминания информации, поскольку они тоже помогают её структурировать.
Эффект Ресторффа – эффект изоляции. В нашей памяти произвольно выделяется объект, отличающийся от остальных какими-то выдающимися признаками. Среди флагов всех стран самый запоминающийся – флаг Канады, потому что ни на одном флаге больше нет кленового листа. Флаг Японии – тот же принцип: алый круг посередине. Можно также выделить какой-либо отдельный признак – так запомнить объект намного легче.
Эффект края основан на автоматизированной сборке и на том, что мы привыкли запоминать ту информацию, которая находится в начале, а также в конце структурного ряда. Мы подсознательно лучше запоминаем то, что у нас было впервые: первая любовь, первая учительница, даже зарплата. То же самое касается того, что случилось в последний раз. Эффект края может использоваться в структурировании информации, если на первое, последнее место выносить наиболее яркие, значимые моменты – на них будет строиться каркас мысленных связей.
Все приведённые методы, эффекты структурирования информации должны создаваться таким образом, чтобы вам, и только вам было удобнее запоминать информацию. Сочетать все перечисленные методы – вполне возможно.
В заключение отметим, что структурирование информации – вещь полезная, нужная, особенно если требуется запоминать большие объёмы информации. В этой статье мы постарались максимально подробно рассказать об этом понятии, надеемся, полученные знания пойдут вам на пользу.
Дополнительное образование
| Информационно-коммуникационные технологии | Формы обучения | Количество часов |
|---|---|---|
| Интернет-технологии в деятельности государственных и муниципальных служащих new | очно-заочная | 18 |
| Работа в графических редакторах Corel Draw и Photoshop | вечерняя, очная | 16 |
| Использование средств информационно-коммуникационных технологий в электронной образовательной среде | очно-заочная, с использованием дистанционных технологий | 72 |
| Cisco Certified Network Associate. 6.0.0 Routing and Switching | очно-заочная, с использованием дистанционных технологий | 432 |
| Информационные технологии в автоматизации делопроизводства учреждений здравоохранения | заочная, с использованием дистанционных технологий | 36 |
| Компьютерное просвещение — старшему поколению | очная | 40 |
| Информационные технологии в государственном и муниципальном управлении | очная | 36 |
| MICROSOFT EXCEL | очная | 40 |
| Microsoft Excel. Расширенные возможности (продвинутый уровень) | очная | 28 |
| SMM – МЕНЕДЖМЕНТ | очная | 52 |
| SMM и КОНТЕНТ – МЕНЕДЖМЕНТ | очная | 64 |
| Cisco Certified Network Associate (Exploration) | дистанционная, очно-заочная | 432 |
| Методы работы с различными структурами данных в языке программирования Паскаль | очная | 24 |
| Профессия «Оператор электронно-вычислительных и вычислительных машин» | очная | 332 |
| Цифровые технологии в педагогическом образовании | очно-заочная, с использованием дистанционных образовательных технологий | 72 часа |
| Экономика и бухгалтерский учёт | ||
| «Налогообложение, ведение учета, составление отчетности в бюджетных, автономных и казенных учреждениях с учетом изменений в 2018 году. Федеральные стандарты учета.» | очная | 18 часов |
| Управление цепями поставок | очно-заочная | 308 |
| Транспортная логистика | очно-заочная, с использованием дистанционных технологий | 94 |
| Бухгалтерский учёт в коммерческой организации | очно-заочная | 194 |
| «Организация и ведение кадрового делопроизводства на предприятии. Рекрутинг» | очно-заочная | 224 |
| Экономика и управление в организации | очно-заочная | 350 |
| Интерпретация и анализ бухгалтерской (финансовой) отчетности | очная, с использованием дистанционных технологий | 252 |
| Специалист по документационному обеспечению управления организацией | либо без отрыва от работы), очная (с полным отрывом от производства), с использованием дистанционных образовательных технологий, с использованием дистанционных образовательных технологий. – заочная (с частичным отрывом от работы | 252 |
| Бухгалтерский учет, налогообложение | очная с использованием дистанционных технологий | 360 |
| Бухгалтерский учёт в коммерческой организации, ведение кадрового делопроизводства на преприятии | очно-заочная | 276 |
| Автоматизированные системы бухгалтерского учета 1С: Бухгалтерия | очная | 80 |
| Бухгалтерский учёт, анализ | очно-заочная | 502, 8 месяцев, 3 раза в неделю |
| Основные изменения в законодательстве о бухгалтерском учете и отчетности в 2019 году. Новые федеральные стандарты бюджетного учета. | заочная, с использованием дистанционных технологий | 40 |
| Автоматизированные системы в бухгалтерском учете: 1С: Бухгалтерия и 1С: Зарплата и управление персоналом | либо заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная | 150 |
| Специалист по документационному обеспечению управления организацией | очно-заочная | 252 |
| РЫНОК ЭЛЕКТРОЭНЕРГИИ: ЧТО НУЖНО ЗНАТЬ, ЧТОБЫ НЕ ПЕРЕПЛАЧИВАТЬ И ПОЛУЧАТЬ ВЫГОДУ | очная с использованием дистанционных технологий | 16-144часов |
| Архитектура и строительство | ||
| BIM: технологии информационного моделирования в эксплуатации объектов капитального строительства | очная, очно-заочная, с использованием дистанционных образовательных технологий | 72 часа |
| Безопасность строительства и качество устройства автомобильных дорог и аэродромов | вечерняя, очно-заочная | 72 |
| Безопасность строительства и качество устройства электрических сетей и линий связи | вечерняя, очно-заочная | 72 |
| Безопасность строительства. Организация строительства, реконструкции и капитального ремонта | вечерняя, очно-заочная | 72 |
| BIM: технологии информационного моделирования в проектировании объектов капитального строительства | очная, очно-заочная, с использованием дистанционных образовательных технологий | 72 часа |
| BIM: технологии информационного моделирования в строительстве | очная, очно-заочная, с использованием дистанционных образовательных технологий | 72 часа |
| «Базовый курс АrchiCAD: практика разработки проектной документации» | очная | 72 |
| БС-15 Безопасности строительства и осуществление строительного контроля | очно-заочная, с использованием дистанционных технологий | 72 |
| Безопасность строительства и качество возведения каменных, металлических и деревянных строительных конструкций | вечерняя, очно-заочная | 72 |
| Безопасность строительства и качество выполнения фасадных работ, устройства кровель, защиты строительных конструкций, трубопроводов и оборудования | вечерняя, очно-заочная | 72 |
| Безопасность строительства и качество устройства инженерных систем и сетей | вечерняя, очно-заочная | 72 |
| Безопасность строительства и качество выполнения общестроительных работ | вечерняя | 102 |
| Безопасность строительства и качество возведения бетонных и железобетонных строительных конструкций | вечерняя, очно-заочная | 72 |
| Безопасность строительства и качество выполнения геодезических, подготовительных и земляных работ, устройства оснований и фундаментов | вечерняя, очно-заочная | 72 |
| Дополнительное образование работников высшей школы | ||
| Использование средств информационно-коммуникационных технологий в электронной образовательной среде | очно-заочная, с использованием дистанционных технологий | 72 |
| Преподаватель в сфере высшего образования | очно-заочная | 260 |
| Внедрение проектного обучения в вузах | очная | 16 |
| Тренинг как метод обучения студентов | очная | 18 |
| Государственное и муниципальное управление | ||
| Интернет-технологии в деятельности государственных и муниципальных служащих new | очно-заочная | 18 |
| Альтернативные способы разрешения конфликтных ситуаций | либо заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная | 18 |
| Информационные технологии государственного и муниципального управления | Очная или заочная (без отрыва от работы) с применением ДОТ. | 18 |
| Кадровое обеспечение муниципального управления. | в режиме вебинара, очно-заочная, с использованием дистанционных технологий | 16 часов |
| Государственная национальная политика: противодействие ксенофобии, экстремизму | очная | 18 |
| Муниципальный контроль | заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная с отрывом от работы | 18 |
| Организационно-правовые основы деятельности центров социального обслуживания | заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная | 18 |
| Основы нотариата для муниципальных служащих | очно-заочная, с использованием дистанционных технологий | 16 |
| Основы управления проектами в системе органов государственной власти и органах местного самоуправления | очно-заочная, с использованием дистанционных технологий | 18 |
| Осуществление взаимодействия со СМИ, связи с общественностью | очная | 18 |
| Регулирование жилищно-коммунального хозяйства и строительства | заочная, очная, с использованием дистанционных технологий | 18 |
| Регулирование земельных отношений, геодезии и картография | заочная, очная, с использованием дистанционных технологий | 18 |
| Регулирование муниципальной службы | очная | 18 |
| Регулирование сельского хозяйства | заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная | 18 |
| Регулирование труда и социальных отношений | заочная, очная, с использованием дистанционных технологий | 18 |
| Юридическое сопровождение деятельности органа местного самоуправления | заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная | 18 |
| Бюджетная деятельность органов местного самоуправления | заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная с отрывом от работы | 18 |
| Организация и осуществление мероприятий по работе с детьми и молодежью | либо заочная без отрыва от производства (с применением дистанционных образовательных технологий), очная с отрывом от работы | 18 |
| Регулирование образования органами местного самоуправления | очная | 18 |
| Государственное и муниципальное управление (переподготовка) | заочная, с использованием дистанционных технологий | 500 |
| Обеспечение защиты государственной тайны | очная, очно-заочная | 18 |
| Финансы и экономика в деятельности муниципальных органов управления | очная, очно-заочная | 18 |
| Физическая культура и спорт | ||
| Организация и проведение тестирования в рамках Всероссийского физкультурно-спортивного комплекса «Готов к труду и обороне» | очная | 36 |
| Подготовка спортивных судей главной судейской коллегии и судейских бригад физкультурных и спортивных мероприятий Всероссийского физкультурно-спортивного комплекса «Готов к труду и обороне» (ГТО) | очная | 18 |
| Адаптивная физическая культура для людей с нарушением опорно-двигательного аппарата | очно-заочная | 72 |
| Физическая культура в образовательных организацииях | очно-заочная, с использованием дистанционных технологий | 260 |
| Физическое воспитание и спортивная подготовка | очно-заочная | 260 |
| Профессиональная деятельность тренера в условиях реализации федеральных стандартов спортивной подготовки | очно-заочная | 72 |
| Менеджмент | ||
| Оценка стоимости интеллектуальной собственности и нематериальных активов new (звоните, изучаем спрос) | дистанционная, очно-заочная | 72 |
| Управление персоналомnew | вечерняя, очно-заочная | 506 |
| Оценка стоимости предприятия (бизнеса) new | дистанционная | 918 |
| Менеджмент: Управление качествомnew | вечерняя | от 500 |
| Оценочная деятельностьnew (звоните, изучаем спрос) | дистанционная, очно-заочная | 104 |
| Стоимость бизнеса: оценка и управление new (звоните, изучаем спрос) | дистанционная, очно-заочная | 40 |
| Основы управления проектамиnew (звоните, изучаем спрос) | дистанционная, очная | 72 |
| Менеджмент в образованииnew | дневная | 504 |
| Кадровое делопроизводство и правовое регулирование трудовых отношений | вечерняя | 72 |
| Логистика (переподготовка) | очно-заочная | 260 |
| Менеджер по персоналу | вечерняя, очно-заочная | 120 |
| Менеджер по персоналу. Рекрутёр | вечерняя | 180 |
| Менеджмент продаж | вечерняя, очно-заочная | 40 аудиторных |
| Офис-менеджер | вечерняя, очно-заочная | 138 |
| Офисные компьютерные программы (Word, Excel) | очно-заочная | 72 |
| Работа в графических редакторах Corel Draw и Photoshop | вечерняя, очная | 16 |
| Эффективный менеджмент | очная | 32, 36, 40 в зависимости от стажа слушателя |
| Оперативный менеджмент | очная | 8 |
| Эффективный менеджмент | очно-заочная | 72 |
| Экономика и управление в организации | очно-заочная | 350 |
| Мастер презентации | очная | 36 |
| Логистический менеджмент | очная | 230 |
| Технологии бизнес-образования (переподготовка) | очно-заочная | 502 |
| Администрирование офиса, ведение кадрового делопроизводства на предприятии | очно-заочная | 222 |
| Администрирование офиса, делопроизводство | очно-заочная | 138 |
| Менеджмент организации | вечерняя, очная | 502 |
| Практикум по бухгалтерскому учету на базе «1 С: Бухгалтерия» | вечерняя, очная | 72 |
| Менеджмент продаж (для продавцов) | вечерняя, очно-заочная | 40 |
| Менеджер в сфере туризма | очная с использованием дистанционных технологий | 36 |
| СИСТЕМА МЕНЕДЖМЕНТА КАЧЕСТВА ВУЗА НА ОСНОВЕ МС ИСО СЕРИИ 9000. ВНУТРЕННИЙ АУДИТ СИСТЕМЫ МЕНЕДЖМЕНТА КАЧЕСТВА | очная с отрывом от работы | 18 |
| Личностный рост топ-менеджера: найди свой внутренний резерв | очно-заочная | 72 |
| Образовательный менеджмент | очная, с использованием дистанционных технологий | 260 |
| Общественно-государственное управление учреждением социальной сферы (образование, культура, социальная защита) | вечерняя, дневная | 72 |
| Юриспруденция и право | ||
| Юрист в сфере ЖКХnew | очно-заочная | от 72 |
| Контрактная система в сфере закупок товаров, работ, услуг для обеспечения государственных и муниципальных нужд (руководитель контрактной службы,40 ч.) | очно-заочная | 40 |
| Коррупция: причины проявления, противодействия (изучаем спрос, звоните) | очная | 72 |
| Организационно-правовые основы деятельности органов ЗАГС | очная, с отрывом от работы | 36 |
| Организация деятельности секретаря судебного участка | очная, с отрывом от работы | 36 |
| Организация судебного заседания в федеральных судах, правовые основы противодействия коррупции | очная | 72 |
| Основы государственного и муниципального управления управления (изучаем спрос, звоните) | с использованием дистанционных технологий | 16 |
| Профессиональная этика и служебное поведение государственных и муниципальных служащих (изучаем спрос, звоните) | очная | 72 |
| Медиация:базовый курс | дневная | 120 |
| Применение интерактивных методов при обучении практическим профессиональным навыкам юриста | очно-заочная, с использованием дистанционных технологий | 72 |
| Государственная национальная политика: противодействие ксенофобии, экстремизму | очная | 18 |
| Государственная политика в сфере противодействия коррупции | очная | 18 |
| Контрактная система в сфере закупок товаров, работ, услуг для обеспечения государственных и муниципальных нужд (работник контрактной службы, 72 часа) | очная, с использованием дистанционных технологий | 72 |
| Специалист в сфере закупок | заочная, с использованием дистанционных технологий | 250 |
| Деятельность в сфере юриспруденции | заочная, с использованием дистанционных технологий | 560 ч.; Срок обучения — 4 месяца |
| Контрактная система в сфере закупок товаров, работ, услуг для обеспечения государственных и муниципальных нужд (специалист в сфере госзакупок,120 часов) | очная, с использованием дистанционных технологий | 120 |
| Подготовка арбитражных управляющих | очно-заочная | 572, срок обучения по программе подготовки арбитражных управляющих |
| Формирование и развитие антикоррупционной мотивации профессиональной деятельности федеральных государственных гражданских служащих | очная, с отрывом от работы | 18 |
| Культура и история | ||
| Повышение квалификации работников культуры «Социокультурный менеджмент» (изучаем спрос, звоните)new | очно-заочная | 72 |
| Повышение квалификации работников библиотек new (изучаем спрос, звоните) | очно-заочная | 72 |
| Обработка металлов | ||
| Профессия «Токарь» | очная | 332 |
| Профессия «Фрезеровщик» | очная | 340 |
| Педагогическое направление | ||
| Программа профессиональной переподготовки «Современное школьное химическое образование» new (изучаем спрос, звоните) | дневная | 500 |
| Вопросы повышения профессионального уровня школьных библиотекарей (изучаем спрос, звоните)new | очно-заочная | от 16 |
| Переподготовка учителей изобразительного искусства и технологииnew | смешанно-дистанционная | 502 часа |
| Преподавание изобразительного искусства в начальных классах | очно-заочная | 502 |
| Преподавание изобразительного искусства и МХК в условиях внедрения профстандарта | очно-заочная, с использованием дистанционных технологий | 502 |
| Образовательный менеджмент | очная, с использованием дистанционных технологий, с отрывом от работы | 260 |
| Педагогика дошкольной образовательной организации | очная, с использованием дистанционных технологий, с отрывом от работы | 260 |
| Инновационные технологии в образовании | дистанционная, заочная, с использованием дистанционных технологий | 18 |
| Разработка и реализация индивидуально-ориентированных образовательных программ (логопедическое сопровождение детей с ограниченными возможностями здоровья) | очная в форме стажировки | 72 |
| Преподаватель средних профессиональных образовательных организаций | очно-заочная | 260 |
| Разработка и реализация индивидуально-ориентированных программ (организация исследовательской инновационной деятельности) | очная в форме стажировки | 72 |
| Преподавание изобразительного искусства и МХК в условиях внедрения ФГОС | заочная | 502 |
| «Психология и педагогика: краткий базовый курс» | дистанционная, очно-заочная | 72 |
| Преподавание технологии в условиях внедрения ФГОС | очно-заочная | 250 |
| Проектная организация образовательного процесса в условиях реализации ФГОС | очно-заочная, с использованием дистанционных технологий | 108 |
| Проектная организация образовательного процесса в условиях реализации ФГОС | , очно-заочная | 16 |
| «Специальное (дефектологическое) образование. “Логопедия. Олигофренопедагогика”» | очно-заочная, с использованием дистанционных технологий | 570 |
| Физическая культура в образовательных организацииях | очно-заочная | 504 |
| Физическая культура в образовательных организацииях | очно-заочная, с использованием дистанционных технологий | 260 |
| Преподаватель изобразительного искусства | очно-заочная | 260 |
| СИСТЕМА МЕНЕДЖМЕНТА КАЧЕСТВА ВУЗА НА ОСНОВЕ МС ИСО СЕРИИ 9000. ВНУТРЕННИЙ АУДИТ СИСТЕМЫ МЕНЕДЖМЕНТА КАЧЕСТВА | очная с отрывом от работы | 18 |
| Инклюзивное высшее образование: организация и спопровождение образовательного процесса | очная | 16 |
| Педагогика образовательной организации | очная, с использованием дистанционных технологий | 260 |
| Профилактика суицида детей и подростков | очно-заочная | 72 |
| Инженерные специальности | ||
| Оперативное управление электрическими сетями 0,4-35 кВ | очная | 72 |
| Оперативное управление электрическими сетями 35-110 кВ | очная | 72 |
| Медицинское оборудование, приборы, системы и комплексы: техническое обслуживание, ремонт и списание | очная | 110 |
| Наладчик обрабатывающих центров с числовым программным управлением | очная | 144 |
| Оператор станков с программным управлением | дневная, очная | 144 |
| «Управление беспилотными летальными аппаратами» | очная | 32 |
| Проектная деятельность | ||
| Проектное управление | очная | 16 |
| Повышения квалификации Управление проектами и программами в организациях в сфере образования | очная | 72 |
| Тьюторское сопровождение проектной деятельности | очно-заочная | 72 |
| Управление проектами в сфере маркетинга ПРО | очная | 104 |
| Тактильная практика | ||
| Омолаживающий самомассаж лица | очная | 12 часов (4 встречи) |
| Психологическое направление | ||
| Психологическая коррекция свойств личностиnew | дневная | 72 |
| Разработка и реализация индивидуально-ориентированных программ (социальная психология развития) | очная | 72 |
| Психологическая поддержка профессиональной деятельности специалистов психолого-педагогического направления | очная, с отрывом от работы | 72 (предполагаются 8 встреч в течение 4-х месяцев: 2 встречи в месяц по 6-7 часов) |
| Библиотечное дело | ||
| Создание информационной продукции библиотеки. Методы профилактики профессионального выгорания | заочная, с использованием дистанционных технологий | 106 |
| Иностранные языки | ||
| Разговорный английский язык | очная | 72 |
| «Campus International: Английский для академической мобильности» | очная | 84 |
| Итальянский язык. Начальный уровень | очная | 64 |
| Переводчик в сфере профессиональной коммуникации | очная | 1200 часов, 20 месяцев |
| Немецкий язык. Второй уровень | очная | 180 |
| Немецкий язык. Начальный уровень | очная | 180 |
| Корейский язык. | очная | 64 часа за один модуль, 4 месяца |
| Сфера услуг | ||
| Профессия «Продавец непродовольственных товаров (широкий профиль)» | очно-заочная | 1040 |
| Профессия «Маникюрша» | очная | 280 |
| Специалист в сфере социального обслуживания | заочная, с использованием дистанционных технологий | 252 |
| Подготовительные курсы | ||
| Физика (подготовка для поступления) | очная | 24 |
| Биология | очная | 96 |
| Журналистика (творческий экзамен) | очная | 20 |
| История | очная | 84 |
| Композиция | очная | 24 |
| Математика | очная | 108 |
| Обществознание | очная | 84 |
| Рисунок | очная | 233 |
| Русский язык | очная | 90 |
| Физика | очная | 96 |
| Химия | очная | 105 |
| Математика (подготовка для поступления) | очная | 24 |
| Программа дополнительного образования детей и взрослых по общеобразовательному предмету Обществознание | очная | 72 |
| Лесное хозяйство | ||
| Государственное управление лесным хозяйством | очная | Очная форма, 72 часа |
| Лесное дело | очная | 500 |
| Организация лесопатологических обследований и проведение санитарно-оздоровительных мероприятий | очная | Очная форма, 72 часа |
| Повышение квалификации вальщиков по проведению выборочных вырубок без предварительного отбора и отметки вырубаемых деревьев | очная | Очная форма, 72 часа |
| Повышение квалификации охотничьих инспекторов | очная | Очная форма, 72 часа |
| Повышение квалификации руководителей тушения лесных пожаров | очная | очная форма, 72 часа |
| Фармация | ||
| Цикл повышения квалификации провизоров, фармацевтов и врачей по направлению «Правила работы с наркотическими средствами и психотропными веществами» | дистанционная | 72 |
| Аптечный мерчандазинг | заочная, заочная без отрыва от производства (с применением дистанционных образовательных технологий) | 36 |
| Основы фармацевтического консультирования при синдроме «красного глаза» | заочная, заочная без отрыва от производства (с применением дистанционных образовательных технологий) | 36 |
| Правила отпуска лекарственных препаратов в розничных фармацевтических организациях. Фармацевтическая экспертиза рецепта | заочная, заочная без отрыва от производства (с применением дистанционных образовательных технологий) | 36 |
| Симптоматическое лечение острых респираторных вирусных инфекций | заочная, заочная без отрыва от производства (с применением дистанционных образовательных технологий) | 36 |
| Фальсифицированные лекарственные средства: контрольно-аналитические аспекты | заочная, заочная без отрыва от производства (с применением дистанционных образовательных технологий) | 36 |
| Фармацевтическая технология | очно-заочная, с использованием дистанционных технологий | 504 |
| Цикл переподготовки провизоров по специальности «Управление и экономика фармации» | дистанционная, очно-заочная | 504 |
| Цикл повышения квалификации провизоров по специальности «Фармацевтическая технология» | дистанционная, очно-заочная | 144 |
| Цикл повышения квалификации провизоров по специальности «Фармацевтическая химия и фармакогнозия» | дистанционная, очно-заочная | 144 |
| Цикл повышения квалификации фармацевтов по специальности «Фармация» | дистанционная, очно-заочная | 144 |
| Цикл повышения квалификации провизоров по специальности «управление и экономика фармации» | дистанционная, очно-заочная | 144 |
| Профессиональная переподготовка по специальности фармация | дистанционная, очно-заочная | 504 |
| Транспорт | ||
| Эксперт по техническому контролю и диагностике автомототранспортных средств | дневная | 512 |
| Диспетчер автомобильного и городского наземного электрического транспорта | очно-заочная, с использованием дистанционных технологий | 264 |
| Контролер технического состояния автотранспортных средств | очно-заочная, с использованием дистанционных технологий | 264 |
| Контролер технического состояния городского наземного электрического транспорта | очно-заочная, с использованием дистанционных технологий | 264 |
| Специалист, ответственный за обеспечение безопасности дорожного движения | очно-заочная, с использованием дистанционных технологий | 264 |
| Контраварийная подготовка водителей | очная | 12 часов |
| Педагогические основы деятельности мастера производственного обучения по подготовке водителей автотранспортных средств | очная с использованием дистанционных технологий | 32 часа |
| Педагогические основы деятельности преподавателя по подготовке водителей автотранспортных средств | очная с использованием дистанционных технологий | 32 часа |
| Программа профессиональной подготовки повышение квалификации ежегодные занятия с водителями | очная | 20 часов |
| Педагогические основы деятельности мастера производственного по подготовке водителей автотранспортных средств | очная | 90 часов — первичное, 72 часа — вторичное обучение |
| Педагогические основы деятельности преподавателя по подготовке водителей транспортных средств | очная | 84 часа — первичное обучение, 72 часа — вторичное обучение |
| Медицина | ||
| Сестринское дело (бакалавриат) | очно-заочная, с отрывом от работы | 144 |
| Офтальмология | вечерняя, очная | 144 |
| Медицинский массаж (дополнительная общеобразовательная программа) | очная | 288 часов |
| Основы лечебного массажа (базовые техники). | очная | 144 |
| «Управление сестринской деятельностью» | очно-заочная | 144 |
| Программа профессиональной переподготовки по специальности «Остеопатия» | очно-заочная | 3504 |
| Медицинский массаж | дистанционная, очная | 288 часов |
| Проектная деятельность в практическом здравоохранении | очная | 324 |
| Функциональная диагностика | очная | 504 |
| Особенности профилактики, диагностики и лечения коронавирусной инфекции COVID-19 | очно-заочная, с использованием дистанционных образовательных технологий | 36 |
| Кардиология (переподготовка) | вечерняя, очная | 576 |
| Кардиология (повышение квалификации) | вечерняя, очная | 144 |
| Общая врачебная практика (семейная медицина) | дневная | 876 |
| Офтальмология | вечерняя, очная | 504 |
| Педиатрия | очная | 504 |
| УЗИ (повышение квалификации) | вечерняя, дневная | 144 |
| УЗИ (профессиональная переподготовка) | вечерняя, очная | 504 |
| Функциональная диагностика | вечерняя, дневная | 144 |
| Стоматология ортопедическая (повышение квалификации) | вечерняя, очная | 144 |
| Стоматология терапевтическая (повышение квалификации) | очная | 144 |
| Стоматология хирургическая (повышение квалификации) | очная | 144 |
| Цикл переподготовки врачей «Стоматология терапевтическая» | очно-заочная | 504 |
| Цикл переподготовки врачей (стоматология ортопедическая) | очно-заочная | 504 |
| Цикл переподготовки врачей (стоматология хирургическая) | очная, с отрывом от работы | 504 |
| Организация здравоохранения и общественное здоровье (переподготовка) | вечерняя | 576 |
| Общая врачебная практика (семейная медицина) | дневная | 144 |
| Хирургия | дневная | 144 |
| Терапия | дневная | 144 |
| Повышение квалификации врачей по специальности «Организация здравоохранения и общественное здоровье» | очная | 144 |
| Медицинский массаж | очная | 288 часов |
| БЕРЕЖЛИВАЯ ПОЛИКЛИНИКА | очная с использованием дистанционных технологий | 16-144 часа |
| Делопроизводство | ||
| Секретарь руководителя | очная | 72 |
| Специалист по кадровому делопроизводству | очно-заочная, с использованием дистанционных технологий | 252 |
| Охрана труда | ||
| Обучение и повышение квалификации по охране труда | дневная, смешанно-дистанционная | 40 ч. — проверка знаний требований охраны труда, 72 ч. — повышение квалификации |
| Биология и химия | ||
| Основы работы в лаборатории | очная | 72 |
| Обучение первой помощи | ||
| Инструктор по обучению навыкам оказания первой помощи | очно-заочная, с использованием дистанционных технологий | 72 |
| Управление персоналом | ||
| Кадровое делопроизводство_138 | очно-заочная | 138 ч, 3 месяца. 2 раза в неделю |
| Кадровое делопроизводство_44 | заочная, с использованием дистанционных технологий | 44 |
| Персонал-менеджмент (переподготовка) | очно-заочная | 502 |
| Организация и ведение кадрового делопроизводства на предприятии | очно-заочная | 232 |
| ОРГАНИЗАЦИЯ ЭФФЕКТИВНОЙ ДЕЯТЕЛЬНОСТИ И КОММУНИКАЦИЙ МНОГОФУНКЦИОНАЛЬНОГО ЦЕНТРА | очная | 48 |
| Агропромышленный комплекс | ||
| Менеджмент в АПК | очно-заочная | 504 |
| Графика и дизайн | ||
| Работа в графических редакторах Corel Draw и Photoshop | вечерняя, очная | 16 |
| Профессия «Декоратор витрин» (звоните, изучаем спрос) | очная | 332 |
| Экологическая безопасность | ||
| Обеспечение экологической безопасности при работах в области обращения с опасными отходами | очно-заочная | 112 |
| Обеспечение экологической безопасности руководителями (специалистами) общехозяйственных систем управления | очно-заочная | очная форма, с применением дистанционных образовательных технологий, 72 часа |
| профессиональная подготовка диц на право работы с отходами I-IV классов опасности | очная с использованием дистанционных технологий | 112 |
| Специалист по экологической безопасности (в промышленности) | очно-заочная | очная форма, с применением дистанционных образовательных технологий, 510 часов |
| Экология и природопользование | очно-заочная | очная форма, с применением дистанционных образовательных технологий, 260 часов |
| Дополнительные общеобразовательные программы для взрослых | ||
| «Компьютер это просто» программа для детей и взрослых | очная | 50 |
| Базовый курс ArchiCAD: практика разработки проектной документации | очная | 72 |
| Основы компьютерной грамотности | очная, с использованием дистанционных образовательных технологий. | 24 |
| Служение сестры милосердия в медицинских социальных учреждениях | очная | 150 |
| «Основы компьютерной грамотности» | очная | 32 |
| культура | ||
| Создание информационной продукции библиотеки. Методы профилактики профессионального выгорания | заочная, с использованием дистанционных технологий | 106 |
| Логистика | ||
| Управление цепями поставок | очно-заочная | 308 |
| Информационные системы и технологии в логистике 1 С «Управление торговлей» | очно-заочная | 28 |
| Производство радиоаппаратуры и аппаратуры проводной связи | ||
| Профессия «Монтажник радиоэлектронной аппаратуры и приборов» (изучаем спрос, звоните) | очная | 332 |
| Кадастровая деятельность | ||
| Актуальные вопросы законодательства в области кадастровой деятельности | очная | 40 |
| Современные технологии в области кадастровой деятельности | заочная с применением средств электронного дистанционного обучения., очная | 40 |
| Механосборочные и ремонтные работы | ||
| Профессия «Слесарь по ремонту автомобилей» (звоните, изучаем спрос) | очная | 332 |
| Профессия «Слесарь ремонтник» (звоните, изучаем спрос) | очная | 332 |
| Профессия «Электромонтер линейных сооружений телефонной связи и радиофикации» | очная | 332 |
| Профессия «Электромонтер по ремонту и обслуживанию электрооборудования» (звоните, изучаем спрос) | очная | 332 |
| Государственные и муниципальные услуги | ||
| Внедрение принципа бережливого производства в многофункциональных центрах | очная | 28 |
| Беспилотные авиационные системы | ||
| Беспилотные авиационные системы и спутниковые технологии | очно-заочная, с использованием дистанционных образовательных технологий | 260 |
| Оператор наземных средств управления беспилотным летательным аппаратом | очно-заочная, с использованием дистанционных образовательных технологий | 112 |
| Дополнительные курсы для студентов колледжей | ||
| Разговорный английский язык | очная | 50 |
| Русский язык. Трудности синтаксиса и пунктуации | очная | 50 |
| Углубленный курс изучения математики | очная | 50 |
| Сельское хозяйство | ||
| Декоративное садоводство и ландшафтный дизайн | очно-заочная | 108 |
Что такое структуры данных? — Определение с сайта WhatIs.com
Структура данных — это специализированный формат для организации, обработки, извлечения и хранения данных. Существует несколько базовых и расширенных типов структур данных, каждая из которых предназначена для упорядочивания данных в соответствии с конкретными целями. Структуры данных облегчают пользователям доступ к нужным им данным и работу с ними надлежащими способами. Что наиболее важно, структуры данных формируют организацию информации, чтобы машины и люди могли ее лучше понять.
В информатике и компьютерном программировании структура данных может быть выбрана или разработана для хранения данных с целью использования их с различными алгоритмами. В некоторых случаях основные операции алгоритма тесно связаны с дизайном структуры данных. Каждая структура данных содержит информацию о значениях данных, отношениях между данными и — в некоторых случаях — функциях, которые могут быть применены к данным.
Например, в объектно-ориентированном языке программирования структура данных и связанные с ней методы связаны вместе как часть определения класса.В не объектно-ориентированных языках могут быть функции, определенные для работы со структурой данных, но они технически не являются частью структуры данных.
Почему важны структуры данных?Типичных базовых типов данных, таких как целые числа или значения с плавающей запятой, которые доступны в большинстве языков программирования, как правило, недостаточно для отражения логической цели обработки и использования данных. Однако приложения, которые собирают, обрабатывают и производят информацию, должны понимать, как данные должны быть организованы для упрощения обработки.Структуры данных объединяют элементы данных логическим образом и способствуют эффективному использованию, сохранению и совместному использованию данных. Они предоставляют формальную модель, описывающую способ организации элементов данных.
Структуры данных — это строительные блоки для более сложных приложений. Они разрабатываются путем объединения элементов данных в логическую единицу, представляющую абстрактный тип данных, имеющий отношение к алгоритму или приложению. Примером абстрактного типа данных является «имя клиента», состоящее из строк символов «имя», «отчество» и «фамилия».«
Важно не только использовать структуры данных, но также важно выбрать правильную структуру данных для каждой задачи. Выбор неподходящей структуры данных может привести к замедлению времени выполнения или к зависанию кода. При выборе структуры данных следует учитывать следующие пять факторов:
- Какая информация будет храниться?
- Как будет использоваться эта информация?
- Где данные должны сохраняться или храниться после их создания?
- Как лучше всего организовать данные?
- Какие аспекты управления резервированием памяти и хранилища следует учитывать?
Как используются структуры данных?
Как правило, структуры данных используются для реализации физических форм абстрактных типов данных.Структуры данных — важная часть разработки эффективного программного обеспечения. Они также играют решающую роль в разработке алгоритмов и в том, как эти алгоритмы используются в компьютерных программах.
Ранние языки программирования, такие как Fortran, C и C ++, позволяли программистам определять свои собственные структуры данных. Сегодня многие языки программирования включают обширный набор встроенных структур данных для организации кода и информации. Например, списки и словари Python, а также массивы и объекты JavaScript являются общими структурами кодирования, используемыми для хранения и извлечения информации.
Инженеры-программисты используют алгоритмы, которые тесно связаны со структурами данных, такими как списки, очереди и сопоставления от одного набора значений к другому. Этот подход можно объединить в различных приложениях, включая управление коллекциями записей в реляционной базе данных и создание индекса этих записей с использованием структуры данных, называемой двоичным деревом.
Вот некоторые примеры использования структур данных:
- Хранение данных. Структуры данных используются для эффективного сохранения данных, например для определения набора атрибутов и соответствующих структур, используемых для хранения записей в системе управления базами данных.
- Управление ресурсами и услугами. Ресурсы и службы базовой операционной системы (ОС) включаются за счет использования структур данных, таких как связанные списки для распределения памяти, управления каталогами файлов и деревьев структуры файлов, а также очередей планирования процессов.
- Обмен данными. Структуры данных определяют организацию информации, совместно используемой приложениями, например пакетов TCP / IP.
- Заказ и сортировка. Структуры данных, такие как двоичные деревья поиска, также известные как упорядоченное или отсортированное двоичное дерево, предоставляют эффективные методы сортировки объектов, таких как символьные строки, используемые в качестве тегов. С помощью структур данных, таких как очереди приоритетов, программисты могут управлять элементами, организованными в соответствии с определенным приоритетом.
- Индексирование .Еще более сложные структуры данных, такие как B-деревья, используются для индексации объектов, например, хранящихся в базе данных.
- Ищем. Индексы, созданные с использованием бинарных деревьев поиска, B-деревьев или хеш-таблиц, ускоряют поиск нужного элемента.
- Масштабируемость. Приложения для больших данных используют структуры данных для распределения и управления хранилищем данных в распределенных местах хранения, обеспечивая масштабируемость и производительность.Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных, чтобы упростить выполнение запросов.
Структуры данных часто классифицируются по их характеристикам. Следующие три характеристики являются примерами:
- Линейные или нелинейные. Эта характеристика описывает, расположены ли элементы данных в последовательном порядке, например, в массиве, или в неупорядоченной последовательности, например, в виде графика.
- Однородный или неоднородный. Эта характеристика описывает, все ли элементы данных в данном репозитории относятся к одному типу. Одним из примеров является набор элементов в массиве или различных типов, таких как абстрактный тип данных, определенный как структура в C или спецификация класса в Java.
- Статический или динамический. Эта характеристика описывает, как компилируются структуры данных. Статические структуры данных имеют фиксированные размеры, структуры и места в памяти во время компиляции.Динамические структуры данных имеют размеры, структуры и области памяти, которые могут сжиматься или расширяться в зависимости от использования.
Если структуры данных являются строительными блоками алгоритмов и компьютерных программ, то примитивные или базовые типы данных являются строительными блоками структур данных. Типичные базовые типы данных включают следующее:
- Логическое значение , в котором хранятся логические значения, которые являются истинными или ложными.
- целое число , в котором хранится диапазон математических целых чисел или подсчет чисел.Целые числа разного размера содержат разный диапазон значений — например, 8-битное целое число со знаком содержит значения от -128 до 127, а длинное 32-битное целое число без знака содержит значения от 0 до 4294967295.
- Числа с плавающей запятой , в которых хранится формульное представление действительных чисел.
- Числа с фиксированной точкой , которые используются в некоторых языках программирования и содержат действительные значения, но управляются как цифры слева и справа от десятичной точки.
- Символ , в котором используются символы из заданного преобразования целочисленных значений в символы.
- Указатели, — справочные значения, указывающие на другие значения.
- Строка , которая представляет собой массив символов, за которым следует код остановки — обычно значение «0» — или управляется с помощью поля длины, которое является целочисленным значением.
Тип структуры данных, используемый в конкретной ситуации, определяется типом операций, которые потребуются, или типами применяемых алгоритмов.К различным типам структур данных относятся следующие:
- Массив. Массив хранит набор элементов в смежных ячейках памяти. Элементы одного типа хранятся вместе, поэтому положение каждого элемента можно легко вычислить или получить с помощью индекса. Массивы могут быть фиксированной или гибкой длины.
- Стек . В стеке хранится набор элементов в линейном порядке применения операций. Этот порядок может быть последним вошел — первым ушел (LIFO) или первым пришел — первым ушел (FIFO).
- Очередь . В очереди хранится набор элементов, например, стопка; однако порядок операций может быть только «первым пришел — первым вышел».
- Связанный список. Связанный список хранит набор элементов в линейном порядке. Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.
- Дерево. Дерево хранит коллекцию элементов в абстрактном иерархическом виде. Каждый узел связан со значением ключа, а родительские узлы связаны с дочерними узлами или подузлами. Есть один корневой узел, который является предком всех узлов в дереве.
- Куча. Куча — это древовидная структура, в которой значение ключа, связанное с каждым родительским узлом, больше или равно значениям ключей любого из значений ключей его дочерних узлов.
- График. График хранит коллекцию элементов нелинейным образом. Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети.
- Трие. Дерево, также известное как дерево ключевых слов, представляет собой структуру данных, в которой строки хранятся в виде элементов данных, которые могут быть организованы в виде визуального графа.
- Хеш-таблица. Хэш-таблица, также известная как хэш-карта, хранит коллекцию элементов в ассоциативном массиве, который отображает ключи к значениям. Хеш-таблица использует хеш-функцию для преобразования индекса в массив сегментов, содержащих желаемый элемент данных.
Они считаются сложными структурами данных, поскольку могут хранить большие объемы взаимосвязанных данных. 2).
Вот некоторые примеры из реальной жизни:
- Связанные списки лучше всего подходят, если программа управляет коллекцией элементов, которые не нужно упорядочивать, для добавления или удаления элемента из коллекции требуется постоянное время, а увеличенное время поиска — в порядке.
- Стеки лучше всего подходят, если программа управляет коллекцией, которая должна поддерживать порядок LIFO.
- Очереди следует использовать, если программа управляет коллекцией, которая должна поддерживать порядок FIFO.
- Двоичные деревья удобны для управления коллекцией элементов с родительско-дочерними отношениями, например, семейным деревом.
- Двоичные деревья поиска подходят для управления отсортированной коллекцией, цель которой — оптимизировать время, необходимое для поиска определенных элементов в коллекции.
- Графики работают лучше всего, если приложение анализирует возможности подключения и отношения между группой людей в сети социальных сетей.
Как структурировать вашу программу информационной безопасности
Функция определения помогает определить, что ваша организация должна защищать. Определение деятельности включает определение того, какие активы — как физические, так и информационные — присутствуют в вашем учреждении; как они вписываются в бизнес-среду; и существующее руководство для управления нормативно-правовой средой и средой управления рисками вашей организации.
Все эти действия составляют вашу оценку рисков , оценку угроз, с которыми сталкивается ваше учреждение, вероятности их возникновения и размера ущерба в случае их возникновения.Результаты вашей оценки рисков будут влиять на общую стратегию управления рисками или на то, как вы планируете вести бизнес-операции таким образом, чтобы ограничить риск до приемлемого уровня.
Оценка риска должна выполняться не реже одного раза в год, чтобы подтвердить, достаточно ли существенно изменились ресурсы, приоритеты или бизнес-операции организации, чтобы оправдать изменение стратегии.
Оценка риска кибербезопасности должна классифицировать критически важные информационные активы, выявлять угрозы и уязвимости и сообщать об этом риске необходимому персоналу, в том числе Совету директоров.Однако, прежде чем вы сможете адекватно оценить риск для вашего учреждения, вы должны сначала идентифицировать свой Crown Jewels или ваши наиболее важные информационные активы. «Драгоценности короны» часто очень чувствительны и охраняются, и их потеря, уничтожение или кража могут серьезно повлиять на ваше учреждение.
Выявление угроз
Для выявления потенциальных угроз кибербезопасности ваше финансовое учреждение может использовать внутренние ресурсы, такие как аудиторские отчеты, сканирование уязвимостей и средства обнаружения мошенничества; или внешние ресурсы, такие как сети обмена информацией, такие как Financial Services — Information Sharing and Analysis Center (FS-ISAC) и United States Computer Emergency Readiness Team (US-CERT) .Такой инструмент, как сканер уязвимостей, также часто используется для выявления слабых мест путем сканирования вашей бизнес-среды на предмет хорошо известных и ранее выявленных уязвимостей. Вы также можете протестировать, чтобы определить, действительно ли выявленная уязвимость пригодна для использования.
В ноябре 2014 года Федеральный экзаменационный совет финансовых учреждений (FFIEC) выпустил заявление, в котором финансовым учреждениям всех размеров рекомендуется участвовать в FS-ISAC в рамках их процесса выявления, реагирования и смягчения угроз и уязвимостей кибербезопасности.Кроме того, два общедоступных отчета, которые могут предоставить текущую информацию об угрозах, — это отчет о расследовании утечки данных Verizon и отчет об угрозах интернет-безопасности Symantec . Оба отчета обновляются ежегодно.
Идентификация угроз должна происходить непрерывно в течение года, а не только во время ежегодной оценки рисков. Когда появляются новости о мошенничестве, взломе или другом инциденте, подумайте, уязвима ли и ваша организация. Может ли то же самое случиться с вашим учреждением? Какие средства контроля используются для защиты от угрозы?
FS-ISAC для финансовых учреждений
FS-ISAC предлагает базовое членство для местных банков с активами менее 1 миллиарда долларов, включая «обязательные» услуги, указанные ниже.Небанковские организации также могут получить членство в FS-ISAC. Чтобы получать только самые важные публичные оповещения, самые маленькие общественные организации могут зарегистрироваться в качестве участника, имеющего только критическое уведомление (CNOP). Эта услуга предоставляется бесплатно, но обеспечивает только оповещение общественности о срочных и кризисных оповещениях. Узнайте больше на https://www.fsisac.com/join.
Услуги FS-ISAC для общественных банков:
- FS-ISAC учредила Совет общественных институтов (CIC), чтобы предоставить банкам сообщества форум для обмена информацией.В эту группу добавляются все новые местные банки / члены кредитных союзов.
- FS-ISAC рассылает еженедельные сводные отчеты о рисках всем членам местного банка. Эти отчеты помогают объяснить, как последние риски влияют на банки и их клиентов и как эти риски можно снизить.
- Community Bank FS-ISAC Члены FS-ISAC имеют доступ к FS-ISAC Security Tool Kit, 72-страничному документу, разработанному совместно с общественными учреждениями и предназначенному для обеспечения набора методов обеспечения безопасности, чтобы помочь укрепить программы информационной безопасности банков в свете возрастающих угроз.
- FS-ISAC распространяет данные об угрозах, уязвимостях и инцидентах для всех участников.
Измерение риска
Для эффективного измерения уровня риска вашей организации необходимо разработать метод измерения риска. Один из подходов — присвоить каждому активу высокую, среднюю или низкую стоимость. Рейтинг может быть финансовым, но он также должен учитывать важность актива для вашего бизнеса. Уровень риска этих информационных активов также оценивается как высокий, средний или низкий.Конечный уровень риска зависит от мер по исправлению положения, предпринятых вашим учреждением; смягчающие меры контроля могут снизить общий уровень риска. Например, если резервное копирование выполняется регулярно, риск потери электронного файла может быть низким.
Конфиденциальность, целостность и доступность (CIA) образуют триаду информационной безопасности . Программы информационной безопасности должны быть созданы для обеспечения ЦРУ всех информационных активов, от данных до оборудования и сетей.
Триада информационной безопасности
- Конфиденциальность означает, что информация защищена от несанкционированного доступа или раскрытия.
- Целостность подтверждает достоверность, точность и защиту информации от несанкционированных изменений.
- Доступность гарантирует надежный доступ и использование информации и информационных систем.
Сообщение о риске
Жизненно важно создать процесс, который информирует высшее руководство и Совет директоров о кибер-рисках для вашей организации, о том, как ваша организация в настоящее время управляет этими рисками и снижает их, и кто несет за это ответственность.После того, как оценка рисков разработана, принята и утверждена, ее следует пересматривать и обновлять не реже одного раза в год, чтобы гарантировать выявление новых рисков.
Оценка риска — это один из элементов более крупного процесса управления киберрисками, который должна иметь каждая организация. Генеральные директора должны стремиться создать и внедрить эффективный и устойчивый процесс управления рисками, который обеспечивает надлежащий надзор и обеспечивает эффективное управление рисками кибербезопасности. Ключевые элементы процесса управления рисками включают первоначальную оценку новых угроз; выявление и приоритезация пробелов в текущей политике, процедурах и средствах контроля; а также обновление и тестирование политик, процедур и средств контроля по мере необходимости.
6 Планирование, структура и организация программы | Мировая наука об океане: к комплексному подходу
на этапе планирования и на всех этапах. Разработчики моделей и наблюдатели должны работать вместе на всех этапах разработки и реализации плана программы.
Координация с долгосрочными и миссионерскими агентствами, а также планирование поставокОдной из сильных сторон основных программ была их способность направить значительный объем талантов и научный интерес на решение большой и часто важной научной задачи.Следовательно, эти программы смогли обеспечить поддержку фундаментальных исследований вне NSF. Например, хотя WOCE был инициирован на средства NSF, он получил поддержку от ряда миссионерских агентств. Хотя NSF предоставил значительную долю финансирования для отдельных главных исследователей, другие ресурсы включали вклад персонала, оборудования, спутников и т. Д. (Рис. 4-1). JGOFS также включает важные компоненты NOAA, ONR и NASA. Сомнительно, чтобы такое же количество главных исследователей, работающих в одиночку или в небольших группах, могло бы решить проблему столь значительного масштаба без предоставления им аналогичных ресурсов со стороны федеральных агентств.
В некоторых случаях существующие программы написали свои планы реализации в ожидании появления новых данных дистанционного зондирования. Задержки с предоставлением этих данных ограничили достижение некоторых из первоначальных целей. Возможности использования данных дистанционного зондирования быстро расширяются, поскольку они обеспечивают глобальный временной контекст для программ. В свою очередь, спутниковые данные зависят от высококачественных данных in situ , часто предоставляемых крупными океанографическими программами. Будущие программы, вероятно, будут более тесно координироваться со спутниковыми платформами.
Попытка максимально использовать доступные ресурсы в таком консорциуме спонсоров требует значительного уровня сотрудничества и координации. Эта координация зависит от хорошего постоянного взаимодействия между руководителями программ. Все агентства должны взять на себя обязательство удовлетворить потребности программных целей. Есть недавние примеры, когда агентства не выполняли свои обязательства: исследование процесса JGOFS в Аравийском море США, где ONR в последний момент внесло коррективы в свою поддержку, а Министерство энергетики поддержало U.Глобальная углеродная съемка S. JGOFS была прекращена до завершения программы. Министерство энергетики также преждевременно прекратило поддержку потоков углерода по программе Ocean Margins. В качестве другого примера, Североатлантический эксперимент США WOCE был запланирован совместно с программой NOAA Atlantic Climate Change Program, и NOAA не выполнила свои обязательства. Эти разочарования являются напоминанием о том, что приоритеты устанавливаются по-разному в разных агентствах и для разных агентств, и это необходимо учитывать в процессе планирования.
По определению, научные цели крупных океанографических программ являются всеобъемлющими и часто выходят за рамки дисциплинарных границ, бросая сеть больше, чем программная площадка данного финансирующего агентства, и выходит за рамки миссии одного агентства.По текущим основным программам межведомственная координация насчитывает
человек.Лингвистический, когнитивный и процессинговый подходы
Реферат
Языковая форма меняется в зависимости от передаваемой информации. Некоторые из способов его изменения включают порядок слов, ссылочную форму, морфологическую маркировку и просодию. Соответствующие категории информации включают в себя способ использования слова или его референта в контексте, например, упоминался ли конкретный референт ранее или нет, и играет ли он актуальную роль в текущем высказывании или дискурсе.Сначала мы даем широкий обзор языковых явлений, чувствительных к структуре информации. Затем мы обсудим несколько теоретических подходов к объяснению структуры информации: статус информации как часть грамматики; информационный статус как представление знаний говорящего и слушателя об общих основаниях и / или состояния знаний других участников дискурса; и оптимальный системный подход. Эти несопоставимые подходы отражают тот факт, что в этой области нет единого мнения о том, какие именно категории статуса информации являются релевантными или как они должны быть представлены.Мы рассматриваем возможности будущей работы по объединению этих направлений работы в явных психолингвистических моделях того, как люди кодируют статус информации и используют его для производства и понимания языка.
ЧТО ТАКОЕ ИНФОРМАЦИОННАЯ СТРУКТУРА?
Люди говорят не просто так. Они хотят делиться новостями, общаться с другими, информировать, развлекать или заставлять что-то происходить. Человеческие языки организованы таким образом, чтобы отражать содержание и цель высказываний, то есть информацию, содержащуюся в словах и структурах, составляющих предложения.Эта организация называется информационной структурой , [1,2] или информационным пакетом . [3] В этой статье рассматривается, как информационная структура ограничивает лингвистическую форму, то есть то, как люди говорят вещи.
Информационная структура помогает объяснить, почему люди говорят по-разному. Ораторы постоянно выбирают, как сформулировать свои высказывания. Например, говорящий может сказать Муравьед преследовал белку , Белку преследовал трубкозуб или То, что преследовал трубкозуб, была белка .Белку можно назвать длинной фразой ( Пушистое существо, укравшее мои крекеры) или просто местоимением это . Хотя эти вариации могут описывать одно и то же событие, они прагматически удачны (т.е. уместны) в разных контекстах.
Ученые-лингвисты согласны с тем, что лингвистическая форма меняется в зависимости от информационных соображений, включая то, на что обращает внимание говорящий, на чем говорящий хочет, чтобы адресаты сосредоточились, что считается уже известным, что считается наиболее важным. , или то, что считается справочной информацией.Тем не менее, определение информационной структуры, как известно, варьируется в зависимости от исследователей и тем. Наш обзор отражает эту неоднородность и дает определения информационной структуры, которые важны для каждого обсуждаемого нами явления. Тем не менее, возникают два общих подхода к структуре информации. Многие лингвистические варианты отражают различие между информацией , заданной (т. Е. Ранее известной или обсуждаемой), и информацией , новой . [4] Другие варианты, кажется, отражают различие между темой (т.е. информация, которая является фоновой или предполагаемой) и фокус (то есть то, что выделено или сфокусировано). Эти различия устанавливают информационный статус слова или референта в дискурсе.
В первом разделе этой статьи мы даем обзор того, что такое информационная структура и как она соотносится с четырьмя лингвистическими явлениями: 1) референциальная форма, 2) морфология, 3) порядок слов и 4) просодия. Во втором разделе мы рассмотрим, как это соотносится с основными теориями о структуре, использовании и обработке языка.Затем мы рассматриваем потенциальные психологические механизмы для представления информационной структуры.
КАК ИНФОРМАЦИОННАЯ СТРУКТУРА ОБРАЗУЕТ ЯЗЫК
Ссылка
Информационная структура оказывает сильное влияние на то, как люди относятся к сущностям в мире, включая как введение новых сущностей в дискурс, так и обращение к уже упомянутым сущностям. Это может повлиять на несколько параметров, включая определенность, использование местоимений и модификацию.
Многие языки, включая английский, используют разные выражения для определенной и неопределенной информации.Например, если говорящий только что разговаривал с кем-то о конкретной собаке, говорящий может обратиться к ней с определенным выражением собака или, возможно, даже с местоимением это . Однако, если собака упоминается в разговоре впервые, говорящий может использовать неопределенное выражение собака . В английском языке определенный артикль «the» традиционно считается указанием на то, что существительное специфично и знакомо как говорящему, так и слушающему, в силу того, что оно уже упоминалось в дискурсе.[5,6]
Однако влияние структуры информации на ссылку модулируется реальными знаниями и выводами. Например, определенные не ограничиваются случаями, когда дан референт. Рассмотрим такую фразу, как «». Я пошел на свадьбу, а невеста была в белом, но, к сожалению, гость пролил на нее вино. [7] Здесь свадьба является неопределенной и упоминается впервые, невеста определена, хотя упоминается впервые (т.е. роман определенный), и гость неопределенный и упоминается впервые. Новые определенные сущности встречаются с сущностями, которые всем известны и известны как уникальных (например, луна, небо), а также с уникальными сущностями, о существовании которых можно судить по упомянутым сущностям (например, мы можем вывести невесту из свадьба ; Принц [4] использует термин «выводимый»). Из-за этого процесса вывода некоторые новые определения могут привести к замедлению понимания.[8]
Информационная структура также направляет говорящий выбор существительных, местоимений и других ссылающихся выражений. После упоминания новой замечательной книги говорящий, вероятно, будет использовать местоимение «оно», чтобы ссылаться на книгу в следующих сразу же высказываниях. Использование местоимений обеспечивает эффективный сокращенный способ обозначения уже упомянутых важных референтов и позволяет говорящим избегать чрезмерного повторения. Фактически было показано, что использование имени, когда достаточно местоимения, приводит к трудностям обработки, по крайней мере, при определенных обстоятельствах.[9] Напротив, введение нового референта требует более полных выражений, таких как описание ( осел) , возможно, модификация ( испуганный осел) или имя (Сильвестр ).
Многие исследователи соглашаются, что выбор выражения определяется значимостью или доступностью референта в контексте. Более сокращенные отсылающие выражения (например, местоимения) используются для обозначения более заметных / заметных сущностей, то есть тех, которые более активны или доступны в сознании людей в этот момент дискурса, и более полные отсылающие выражения (например,грамм. существительные) используются для менее значимых сущностей. [10,11] Однако определение значимости / доступности является сложным. Интуитивно, референты становятся доступными, когда они актуальны в недавнем дискурсе — например, когда они были недавно упомянуты, особенно когда они были упомянуты в синтаксически заметных позициях, таких как позиция субъекта. [5, 12, 13] Однако этот эффект имеет место. модулируется грамматической позицией ссылающегося выражения: местоимения в позициях субъекта и объекта обычно интерпретируются как относящиеся к ранее упомянутым объектам в параллельной синтаксической позиции (например,грамм. предшествующий субъект или объект). [14] Интерпретация местоимений также определяется правдоподобием потенциальных референтов, что часто связано с их тематическими ролями. Одним из таких эффектов является неявная причинность события, например in Попугай обвинил тигра, потому что он …., понимающие ожидают, что местоимение будет относиться к тигру. [15] Неявная причинность и другие эффекты семантики глагола модулируются отношением когерентности между двумя предложениями, например, сообщает ли второе предложение причину («… потому что…») или что-то еще.[52] Также кажется, что доступность — это не одно измерение, поскольку разные виды ссылающихся выражений кажутся чувствительными к разным видам информации. Например, финский — это язык с гибким порядком слов, в котором люди могут упоминаться с помощью указательных местоимений («это») или личных местоимений («он / он»). В финском языке указательные местоимения, как правило, коррелируют с поствербальными аргументами (субъектами или объектами), которые, как правило, являются новаторскими для дискурса. В отличие от этого, личные местоимения демонстрируют сильное предпочтение кореференции с синтаксическими субъектами, независимо от их данного / нового статуса или положения предложения.[16,17]
Морфологическая маркировка информационной структуры
Морфология существительного
Во многих языках морфологическая маркировка существительных используется для обозначения грамматической роли. Например, в японском и корейском языках предметы имеют номинативный маркер — ga (японский) и — i / — ka (корейский), а прямые предметы отмечены винительным падежом (- o на японском языке и ). — (l) ul на корейском языке). Эти языки также имеют маркер информационного статуса, который указывает тему, а именно — wa на японском языке и — (n) un на корейском языке [18,19], которые могут встречаться как для субъектов, так и для объектов.И японские, и корейские маркеры темы могут встречаться на тематическом объекте, то есть о том, о чем идет речь в предложении. Когда все предложение представляет собой новую информацию (например, ответ на вопрос «Что случилось?»), Только номинативный маркер является удачным по теме на обоих языках (например, 1a, # обозначает неудачу). Напротив, в контексте, когда одна сущность является актуальной, использование маркера темы на этой сущности более естественно (например, 1b,? Означает, что использование неудобно). И -wa , и — (n) un также могут иметь более тонкую интерпретацию (например,грамм. могут использоваться для обозначения контрастирующих тем), [20] в зависимости от их положения и информационно-структурных свойств остальной части предложения. [21]
Другие языки, такие как язык майя цоциль, также используют морфологические средства для обозначения тем. Тематические фразы в Tzotzil начинаются с частицы a и заканчиваются энклитикой — e . [22] Есть также языки, которые используют морфологию для обозначения сфокусированных, новых информационных элементов, а не тематических элементов (например, в западноафриканском языке группы, такие как Gur, Kwa и Chadic).[23] Даже языки, которые обычно не считаются имеющими морфологические тематические маркеры, показывают признаки того, что морфология чувствительна к информационной структуре. Например, в русском языке объект отрицательного предложения (например, «буква») помечается винительным падежом, когда известно, что буква существует («Он не получил букву-АСС» означает, что он не получил букву), и с родительным падежом, когда существование буквы неизвестно / не предполагается («Он не получил письмо-GEN» означает, что он не получил никакого письма).[24] Связанные шаблоны существуют в финском языке. [25]
Морфология глагола
Некоторые языки отмечают информационный статус аргументов с помощью вербальной морфологии в так называемой обратной системе . В переходных глаголах глагольные наклонения указывают, какой аргумент является «ближайшим» (то есть актуальным и / или данным), а какой — «очевидным» (менее актуальным). Это похоже на функцию пассивного слова в английском языке, поскольку обратная глагольная морфология указывает на то, что аргумент Актера менее актуален, чем другой аргумент.Например, на языке мапуче в Чили, «я» и «вы» считаются более актуальными, чем аргументы от третьего лица, поэтому предложение, означающее Она видела меня , требуется для принятия обратной морфологии, в результате чего предложение, больше похожее на , я видел ее . [26] Обратные системы также были описаны для алгонкинского, чероки и других языков. [27]
Другие маркеры фокуса
Эффекты информационной структуры также очевидны при использовании частиц фокуса, таких как только и даже .[28] Хотя некоторые фокусные частицы являются отдельными словами (например, английский only , too , German nur ‘only’, auch ‘too’), они также могут быть клитиками, которые присоединяются к другим составляющим (например, финский — кин «тоже», яп. -мо «тоже»). Эффект, который эти выражения оказывают на значение предложения, в решающей степени зависит от информационно-структурных свойств предложения: рассмотрим предложение с только , например, Джон видел только собаку. Если увидел — это новая информация, тогда предложение означает, что Джон только ВИДЕЛ собаку, но не гладил ее и не гулял. Но если собака является новой информацией, предложение означает, что Джон видел только СОБАКУ и ничего больше (см. Также раздел о просодии ниже).
Изменение порядка слов
Влияние информационной структуры распространяется на изменение порядка слов или порядка составных частей. Например, одно событие можно описать множеством способов, как показано в (2).(См. [31] для более подробного обсуждения различных конструкций на английском языке.)
(2)
a
Активный: Кошка ударила собаку по носу.
b
Пассивный: Кошка ударила собаку по носу.
c
Heavy-NP-shift: Кот ударил по носу напугавшую его собаку.
d
Тематика: СОБАКА кошка ударила по носу, а хорек убежал.
d
Предложный дательный падеж: Кошка предупредила собаку.
e
Двойной объект Дательный падеж: Кошка предупредила собаку.
f
Расщелина: Это была собака, которую кошка ударила по носу
Широко распространено мнение, что функция изменения порядка слов заключается в маркировке информационной структуры, следуя широкому обобщению что данная или более доступная информация предшествует новой или менее доступной информации.[1,6,29]. Связанный с этим эффект — тенденция помещать длинные и сложные фразы позже в высказывание, а относительно короткие — раньше (например, 2c). [30] Эти два паттерна не являются независимыми, потому что короткие фразы, как правило, относятся к данной и актуальной информации. Тем не менее, есть свидетельства того, что сложность фраз и информационная структура имеют независимое влияние на порядок слов [47].
Примеры в (2) взяты из английского языка, который имеет относительно ограниченное изменение порядка слов, и большая часть изменений происходит из неканонических порядков слов.[31] Многие другие языки, включая финский, японский, корейский, немецкий, турецкий, языки майя и западноафриканские языки, позволяют еще более свободно изменять порядок слов. Как и в английском, порядок слов отражает упаковку информации, как правило, в соответствии с заданным новым порядком. Например, в финском языке субъекты канонически предшествуют объектам, но объекты могут появляться перед субъектами, когда они уже упоминались в предыдущем дискурсе (пример 3) [32]. Порядок слов также можно использовать для обозначения фокуса, как в английском языке (например, расщелины).грамм. Финский заказ OSV и SOV, ex. 3 (в)).
(3)
Что читал Эса?
5 9059 a book3 9058a4 9058a4Esa luki kirjan (финский: SVO) Esa-NOM читать book-ACC Кто читал книгу?
9059 ‘9058‘’/’ Книгу прочитал Эса. ‘Kirjan luki Esa (финский: OVS) Book-ACC luki Esa-NOM Esa-NOM - —
Кирьян Esa luki (финский: OSV) Book-AC86 Esa 905 прочитал «Это была книга, которую прочитал Эса»
Просодия и интонация
В таких языках, как английский, информационная структура отражается в просодии речи. Просодия включает слоговое ударение и интонационную фразировку, а также ритмическую структуру высказывания. Подчасть просодии, интонация , действует независимо от ритмической просодии и отмечает информацию или структуру фокуса предложения. Интонационная структура высказывания определяет, какие слова получают акцентов , то есть какие слова звучат акустически более отчетливо. Акценты обычно реализуются с изменением высоты тона, большей продолжительностью и амплитудой.Интонационный акцент отличает два идентичных предложения, показанных в (4), где заглавные буквы обозначают слова с ударением.
(4a)
У нее была домашняя КРЫСА.
(4b)
У нее была крыса из ПЭТ.
Акцент означает такие категории статуса информации, как фокус, контрастность и данность / новизна. [33] Фокус относится к выделению составляющих в высказывании, которые составляют новости или способствуют достижению целей говорящего.[34] Пример (4) показывает, как фокус может по-разному выделять информацию в высказывании. (4а) правильно отвечает на вопрос типа «Были ли у нее домашние животные?» тогда как (4b) может появиться после «Были ли у нее крысы?» Фокус не обязательно должен относиться к конкретным вопросам.
Акценты также могут обозначать контрастирующий элемент набора сущностей, [35] как в (5):
(5a)
Нет, не ЗЕЛЕНАЯ ящерица, КОРИЧНЕВАЯ.
(5b)
Нет, не зеленая ящерица, а зеленая ЗМЕЯ.
В 5а говорящий обращается к коричневой ящерице, особенно в контрасте с зеленой, с акцентом на цвет. На 5b акцент вместо этого отмечает контраст между двумя сопоставимыми животными, фокусируясь на разных рептилиях. Фокус и контраст часто накладываются друг на друга, как в этом примере, где акцент отражает информационный фокус на одном фрагменте контрастирующей информации.
Наконец, акцент часто отмечает разницу между данной и новой информацией, которая имеет тенденцию быть деакцентированной и акцентированной соответственно, как в (6):
Как и в случае с контрастом, фокус играет ключевую роль в отношениях между акцентом и данностью / новизной. .[36]
Существуют существенные эмпирические доказательства того, что говорящие и слушатели чувствительны к функциям интонации. Ораторы модулируют просодию на основе информационного статуса своих слов, используя акустическое сокращение , (т. Е. Более короткое, безударное и менее внятное произношение) для ранее упомянутых слов или сущностей [37]. Точно так же слушатели быстрее интерпретируют ссылки на данную информацию, если слово без ударения. [38] Однако точная акустика акцентирования и деакцентирования еще полностью не изучена, и необходимы дальнейшие исследования, чтобы понять, как речь отражает лингвистические категории информационного статуса.
ТЕОРЕТИЧЕСКИЕ ПОДХОДЫ К ОБЪЯСНЕНИЮ СТРУКТУРНЫХ ЭФФЕКТОВ ИНФОРМАЦИИ НА ЯЗЫКЕ
Как описано выше, лингвистическая форма очень чувствительна к статусу информации. Почему это происходит? Исследователи предложили множество типов объяснений, от прагматических правил, касающихся языковой формы, до когнитивных механизмов, лежащих в основе использования языка. Здесь мы рассмотрим некоторые из этих подходов.
Первый раздел (именуемый здесь лингвистическим системным подходом) описывает теории, которые фокусируются на природе самой информации.Одна часть этой исследовательской традиции фокусируется на роли, которую информация играет в конкретном дискурсе или предложении. Это актуально? Предпочитает ли выступающий выделить эту информацию? Другое подмножество фокусируется на том, являются ли знания известными или знакомыми. Это состояние знания может быть истолковано как знание говорящего, знание слушателя или и то, и другое.
Второй раздел (называемый здесь социальным / коммуникативным подходом) описывает два совершенно разных теоретических подхода, которые рассматривают, как изменение языковых форм служит цели общения.Подход, основанный на общих принципах, исследует, как участники дискурса отслеживают как свое собственное состояние знаний, так и состояние своих собеседников, и как это определяет использование языка. Оптимальный системный подход также ориентирован на эффективную коммуникацию, но вместо этого учитывает совершенно другой аспект информации — то есть способность языковых форм нести больше или меньше информации, выражаясь количественно.
Статус информации как часть лингвистической системы
Наиболее широко распространенное понятие информационной структуры — это набор правил или ограничений, которые определяют лингвистическую форму целиком или частично.Согласно этой точке зрения, ключевая цель исследования в этой области — определить, какие информационно-структурные категории актуальны и как они влияют на выбор языковой формы. Сюда входят формальные подходы, в которых информационная структура является либо частью грамматики, либо интерфейсом грамматики / прагматики, а также функциональные подходы, в которых когнитивные представления определяют лингвистическую форму.
Категориальные подходы
Одна традиция описывает, как лингвистические системы ограничиваются двоичными (или иногда трехсторонними) различиями в статусе информации.Вообще говоря, этот подход получил значительное внимание в теоретической лингвистике, где исследователи приводят аргументы в пользу различных типов структурно-информационных подразделений (например, тема-комментарий; [39,40] тематический фокус; [41] focuspresupposition; ). [42, 43] rheme-theme; [1] open proposition-focus; [44] см. Также [45] для трехчастного деления). Эти подходы объединяет понимание того, что одна часть каждого высказывания связана с чем-то, что слушатель уже знает, а другая часть предоставляет новую информацию об этом известном объекте или событии.Например, рассмотрим дискурс Маленький коричневый червяк, шевелящийся под салатом. Несколько мгновений спустя он появился из-под земли к обеду. Местоимение he относится к червю, который уже упоминался ранее и может рассматриваться как тема данного фрагмента дискурса. Новую информацию [появившуюся с земли] можно считать фокусом. Информационно-структурные подразделения в предложениях также можно увидеть с помощью щелей, например, . Он съел рукколу .Здесь «руккола» — это новая, сфокусированная информация, в то время как [он что-то ел] — вот о чем идет речь в предложении, которое здесь можно рассматривать как предпосылку или открытое суждение. Таким образом, ключевая часть понимания состоит в том, что слушателям необходимо определить, о чем идет речь (т. Е. Интуитивно, о чем идет речь в предложении), и добавить новую информацию о теме в свою модель ментального дискурса.
Градиентные представления информационного статуса
В то время как теоретическая лингвистика в основном предпочитала категориальные описания категорий информационного статуса (см. Раздел ниже о будущих направлениях), в литературе по функциональной лингвистике предложены градиентные описания информационного статуса.Такое представление, по-видимому, требуется для таких явлений, как вариации в референциальных выражениях, которые подпадают под иерархию специфичности, от безударных местоимений до очень специфических выражений, таких как , эта белка, которая забралась на крыльцо экрана и украла наши взломщики в прошлом году (см. Раздел выше по ссылке). Было предложено, что это изменение является результатом статуса референта по континууму, например, заметность , видимость , доступность или .[3, 10, 11,12,13] Гивон [46] характеризует информацию по континууму актуальности, которая очень похожа на то, что другие исследователи называют доступностью. Обратите внимание, что некоторые исследователи используют термин focus или focus of Внимание , чтобы идентифицировать элемент, который является наиболее заметным в дискурсе; но такое использование термина имеет больше общего с лингвистическим термином «тема», чем «фокус». Предполагается, что недавнее упоминание делает информацию заметной, а также выдающиеся синтаксические позиции, такие как тема или позиция темы.Представления о доступности также учитывают предпочтения в порядке слов [47] и акцентировании [38].
Открытость и актуальность также связаны с предсказуемостью. [12] Дискурсы, как правило, тематически организованы, поэтому уже упоминавшаяся информация, вероятно, будет упомянута снова. Это делает сами слова предсказуемыми, но также делает предсказуемыми ссылки на саму информацию, независимо от того, какие слова используются. [48] Принс [4] даже предлагает одно определение данности, основанное на предположении говорящего о том, что предсказуемо для слушателя.Однако недавняя работа дала неоднозначные результаты относительно того, могут ли говорящие использовать выражения ссылки, например местоимения против имен связаны с предсказуемостью ссылок. В то время как некоторые исследования показывают, что да (12, 49), другие находят, что нет, [50], [51] см. Также [52].
Информационный статус отражает социальную / коммуникативную функцию языка
Общий подход
Существует широкий консенсус в отношении того, что информационный статус имеет отношение к использованию языка, потому что он выполняет социальную функцию.Как знаменито утверждал Грайс [53], ораторы строят свои высказывания так, чтобы удовлетворить требованиям успешного общения. Например, он предлагает, чтобы говорящие следовали принципу количества, то есть столько, сколько требуется, но не больше. Информация, уже установленная в контексте, помогает определить, сколько требуется. Это обобщение хорошо согласуется с кросс-лингвистической тенденцией говорящих производить более конкретные референциальные выражения, когда информация непредсказуема из контекста. С этой точки зрения упаковка информации является результатом языкового соглашения: говорящие могут упорядочивать данную информацию перед новой в результате социального «контракта» [8] со слушателями.
Социально-коммуникативный взгляд на упаковку информации в значительной степени зависит от идеи, что говорящие и слушатели отслеживают, какая информация является взаимно известной, или общей точки зрения . [54] Общая основа может включать социальное или культурное происхождение, лингвистическое происхождение. или окружающая среда, и ожидания относительно хода разговора. Например, общий язык помогает собеседникам понять: когда говорящий говорит, что Капибара очаровательна, он имеет в виду известную в разговоре капибару, а не какую-то другую.Точно так же Принс [55] различает данную дискурсом от данности слушателя.
Спикеры опираются на общую основу для процесса дизайна аудитории , посредством чего они выбирают лингвистические формы, которые соответствуют знаниям и состоянию внимания их собеседников. Например, собеседники обычно устанавливают общий круг ведения, а смена партнеров может привести к снижению эффективности [56]. Выступающие включают необходимые модификаторы (например, «маленький квадрат» в контексте квадратов разного размера), предполагая, что они заметили референтный контраст.[57] Слушатели также отслеживают, какая информация передается говорящему, и быстрее понимают отсылки, такие как красный треугольник , когда есть один красный треугольник в общем основании, [58] и наблюдают за визуальным фокусом внимания говорящего. чтобы помочь интерпретировать неоднозначные определенные описания, такие как круг при наличии нескольких кругов. [59]
С другой стороны, влияние общей основы на производство и понимание языка несколько ограничено.Некоторые исследователи предположили, что, по крайней мере, в некоторых ситуациях, говорящие не используют свою точку зрения при планировании или выполнении высказываний. [60] Слушатели тоже иногда рассматривают объекты в привилегированной области как потенциальные референты, даже если говорящий не знает о присутствии объекта [61].
Таким образом, представления информационного статуса должны включать знания говорящего и слушателя о том, какая информация является общей, а какая нет. Однако, учитывая неоднозначные результаты в этой области, общие основания не предлагают простого механизма для определения информационной структуры.Ораторы отслеживают знания и намеренное состояние своего собеседника, но, похоже, это влияет только на одни языковые процессы, а не на другие.
Оптимальный системный подход
Другой подход к пониманию того, как информация влияет на речь, основан на аргументе, что в зашумленном канале связи, таком как естественная речь, наиболее эффективным способом максимизировать передачу информации является поддержание равномерной передачи информации во времени. [62] Это означает, что когда контекст делает информацию ожидаемой или предсказуемой, говорящие должны стремиться сократить языковые формы, которые кодируют эту информацию.Напротив, они должны кодировать менее предсказуемую информацию с более явным произношением, лексическим и / или синтаксическим выбором. Недавние предложения по плотности информации утверждают, что речь отражает эту рациональную организацию, [63] и что понимающие используют аналогичный метод, основанный на информации, хотя ни говорящие, ни понимающие не обязательно делают эти вычисления сознательно. С этой точки зрения статус информации имеет математическое определение. Информация слова определяется как преобразованная в отрицательный логарифм частота этого слова вне контекста. (I (слово) = log1p (слово) = — журнал (p (слово))).Он измеряет степень уменьшения неопределенности (т. Е. Информации) в слове.
Этот подход учитывает широкий спектр эмпирических явлений. Например, говорящие удлиняют слова, которые относительно непредсказуемы в контексте (т. Е. Несут больше информации), и снижают общую ясность предсказуемых слов. [64] На уровне слов необязательный , что (например, Она знала, что ее лошадь выиграла против Она знала, что ее лошадь выиграла ) встречается чаще, когда плотность информации высока, т.е.е. когда слово менее предсказуемо в контексте. [65] Говоря более абстрактно, говорящие увеличивают информационный вклад предложений по мере развития дискурса. [66] В понимании также слова, которые создают меньше неожиданностей (обратное уменьшение неопределенности) вызывают меньшие трудности обработки, предполагая, что читатели и слушатели отслеживают плотность информации. [67,68]
БУДУЩИЕ НАПРАВЛЕНИЯ: ПСИХОЛОГИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ СОСТОЯНИЯ ИНФОРМАЦИИ
Там Исследователи сходятся во мнении, что языковые формы меняются в зависимости от информационного статуса и информационной структуры.Но теоретические взгляды, изложенные выше, демонстрируют, что все еще существуют существенные различия в измерении информации, которая считается актуальной. Также было мало систематических исследований взаимосвязи между этими различными подходами. Мы утверждаем, что следующим многообещающим шагом в этой области является изучение психологических механизмов, посредством которых информационный статус представлен и используется. Это центр текущих исследований. Здесь мы определяем некоторые предположения, которые вытекают из теоретических подходов, изложенных выше, анализируем существующие предложения о механизмах обработки и выявляем вопросы, требующие дальнейшего внимания.
Прототипная обработка информационного статуса делит высказывания на такие категории, как данное / новое или тема / фокус. Эти категории используются для объяснения того, почему говорящие используют одну лингвистическую форму вместо другой и как понимающие интерпретируют их. Эта точка зрения, по-видимому, предполагает, что система обработки включает явное представление информационного статуса, доступного лингвистическим процессам, управляющим порядком слов, интонацией, выбором ссылочной формы и другими явлениями информационной структуры, а также механизм для выбора правильной формы. .Тем не менее, остается много открытых вопросов как о 1) представлении информационного статуса, так и о 2) механизмах, с помощью которых информационный статус влияет на языковую форму.
Как отображается информационный статус?
Информационный статус как нелингвистическое представление
Одна из возможностей состоит в том, что информационный статус представлен нелингвистическим языком в сознании участников дискурса. Многие модели предполагают, что участники дискурса поддерживают ментальную модель текущей ситуации, которая также включает теги информации-статуса [69] или градиентные представления значимости дискурса.[70]
Другая возможность состоит в том, что наши ментальные репрезентации специально не присваивают теги информационного статуса, а скорее то, что информационный статус возникает естественным образом из человеческой памяти и систем внимания (см. Также [71] о связи между лингвистическими и неязыковыми репрезентациями). ). Теории памяти различают рабочую память, в которой хранится информация, которая используется в данный момент, и долговременная память, в которой хранятся концептуальные и процедурные знания для последующего использования. Мы можем определить «данную» информацию как информацию в рабочей памяти, в то время как «новая» — это информация, которая еще не была извлечена из долговременной памяти (см. [5] для обсуждения).
Подобным образом градиентные различия в заметности или доступности могут соответствовать количеству уделенного внимания. Эта интуиция лежит в основе иерархии «Живучесть» Гунделя и др. [11], которая предполагает, что языковые формы выбираются на основе предположения говорящего о состоянии внимания слушателя. Отношение к вниманию аналогичным образом воплощается в лингвистическом термине «фокус внимания» (относящемся к Обратному центру теории центрирования) [72], который использовался для объяснения референциальной формы, порядка слов и других явлений.
Этот нарождающийся взгляд на представление информации согласуется с предложением Хортона и Джеррига [73] о том, что представления общих оснований являются естественным следствием того, как работает память. Они предполагают, что собеседники автоматически и неявно сохраняют ассоциативную информацию о разговоре (например, о том, кто представил конкретный референт), точно так же, как они хранят информацию вне лингвистического контекста. В связи с этим ораторы затем обращаются к этим ассоциациям, чтобы сделать свой разговорный вклад уместным.Это позволяет им полагаться на собственные знания и простоту обработки даже в некоммуникативных задачах.
Необходимы дополнительные исследования, чтобы понять, как представления информации меняются динамически с течением времени и в зависимости от контекста. Оптимальный системный подход (описанный выше) определяет информацию с точки зрения вероятности слова, референта или структуры. Эта вероятность, в принципе, должна рассчитываться в конкретном контексте. Эта учетная запись приводит к важным вопросам о том, насколько подробным является расчет вероятности, какая информация включена и на каком уровне детализации, а также как быстро она рассчитывается и обновляется.
Статус информации как лингвистическое представление
Другой вопрос заключается в том, представлен ли статус информации явно в синтаксической структуре (см. [2] для обсуждения). Этот вопрос поставлен теоретическим подходом к синтаксису, известным как картографический подход [74, 75]. Одна из основных целей этой работы — исследовать то, что закодировано в грамматике: «Из свойств, которые входят в систему человеческого мышления и убеждений, какие из них представлены как грамматические особенности?» ([74], с.424). Если предложения имеют темы и фокусы, представлены ли эти свойства также как грамматические особенности в синтаксическом представлении предложений? Согласно Рицци [76] и другим, ответ — да. С этой точки зрения, определенные лингвистические элементы «помечены» различными структурными характеристиками информации, и им необходимо найти путь к правильной синтаксической позиции, чтобы «удовлетворить» несущую ими структурно-информационную характеристику. В рамках картографического подхода было проведено большое количество мелкозернистых кросс-языковых работ, которые позволили исследователям выявлять кросс-языковые обобщения, а также различия.
Механизмы использования информации о статусе
Информация как критерий выбора
Информационная структура обычно используется как объяснение того, почему одна лингвистическая форма предпочтительнее другой. Таким образом, информационная структура представляет собой обусловливающий контекст, а лингвистические формы выбираются на основе грамматических или прагматических правил, определяющих это отношение. Это точка зрения, представленная вышеупомянутым картографическим подходом, а также другими прагматическими и грамматическими подходами к структуре информации.Необходима дополнительная работа для разработки психолингвистических моделей этих процессов.
Информационные эффекты посредством облегчения обработки
Другая возможность состоит в том, что информационная структура актуальна, поскольку она имеет последствия для психолингвистических процессов, лежащих в основе языкового образования и понимания. Информацию, которая является предоставленной, обслуживаемой, предсказуемой и актуальной, обычно легче обрабатывать, чем информацию, которая является новой и необслуживаемой. Например, когда информация хорошо представлена в памяти и / или к ней обращаются, ее должно быть легко получить.Было высказано предположение, что это облегчает реактивацию этой информации как во время языкового производства, так и во время понимания, и это напрямую влияет на языковое поведение.
Одно из таких предложений состоит в том, что синтаксический выбор отражает легкость создания различных элементов в высказывании. [77] Ораторы склонны выбирать синтаксические конструкции, которые позволяют им помещать доступную информацию в начале высказывания, возможно потому, что это позволяет им отложить сложную часть высказывания, которая требует дополнительного времени для планирования.[47]. Эта точка зрения подтверждается свидетельствами того, что говорящие выбирают порядок слов в зависимости от их собственного визуального внимания. [78] Связанное с этим предложение состоит в том, что говорящие воспроизводят акустически сокращенные формы для повторяющихся слов, потому что производство данной информации облегчается. [79] В связи с этим, на запоминание понимающим и легкость обработки языковых стимулов влияют устройства для выделения фокуса, такие как щели [80] и акценты высоты тона [81].
Распределение информации
Теоретико-информационные описания языковых вариаций, описанные в разделе об оптимальных системах, предполагают, что языковые формы выбираются таким образом, чтобы обеспечить плавное распределение информации.Прозрачное применение этой литературы предполагает, что система языкового производства имеет систему мониторинга, которая определяет объем информации в конкретной идее и выбирает лингвистические формы, которые распределяют ее равномерно. Такой механизм может напрямую опираться на представления, предлагаемые другими исследовательскими традициями, для количественной оценки информации (например, тема / фокус, данные / новые, знания адресата и т. Д.). В качестве альтернативы, эти эффекты могут быть результатом множества отдельных механизмов, таких как описанные выше.
Заключение
Связь между информационным статусом и лингвистической формой является сложной. Есть много лингвистических явлений, которые чувствительны к информационным соображениям, но не существует единой теории репрезентаций информационного статуса, которая охватывала бы их все. Одна из причин этого в том, что разные лингвистические явления выделяют разные категории информации. Как мы описали выше, разные языки кодируют информацию о статусе с помощью ссылки, порядка слов, морфологической маркировки, просодии и других языковых явлений.Некоторые из них, кажется, требуют категорического разделения между темой и фокусом, или данным и новым. Третьи, похоже, требуют градиентного представления актуальности или предсказуемости.
Частично неоднородность того, как языки кодируют информацию, может происходить из-за широты того, что мы можем назвать «информацией». Мы можем думать об информации как о свойстве вещей в мире, так что некоторая информация либо по своей природе более существенна, либо более существенна, чем другая информация в контексте.В качестве альтернативы, мы могли бы рассматривать информацию как свойство того, как сущности и события в мире представлены психологически, так что некоторая информация имеет более сильные, более подробные или более доступные представления. Другие подходы рассматривают информационную структуру как возникающую часть социального взаимодействия, например, понятие, что «данное» и «новое» определяются относительно общего основания и / или коммуникации посредством зашумленного сигнала. Цель будущей работы — определить, как эти характеристики соотносятся друг с другом и с вариациями в языковой форме.
Обеспечение структуры веб-страниц и документов
Обзор
Чтобы понять документ, каждый зависит от понимания его структуры. Например, рассмотрим текущую веб-страницу. Он включает в себя баннер, несколько меню навигации и основной контент, который вы читаете в данный момент. Основное содержание организовано в разделы, отмеченные заголовками и подзаголовками, а содержание этих разделов состоит в основном из абзацев и списков.Зрячие пользователи понимают все эти отношения с первого взгляда, в основном на основе визуальных символов, таких как размер и положение контента относительно другого окружающего контента.
Пользователи программы чтения с экрана должны понимать эту структуру, как и все остальные. Следовательно, они зависят от авторов контента, четко определяющих заголовки, абзацы, списки, таблицы, баннеры, меню и другие функции именно так, как они есть. В мире веб-дизайна это называется семантикой , построение страницы с использованием веб-элементов, определяющих роль объекта.Например, при добавлении заголовка верхнего уровня на веб-страницу используйте встроенную функцию «Заголовок 1», которую предоставляет ваше программное обеспечение для разработки. Если вы просто сделаете текст большим и жирным, он может выглядеть как заголовок, но на самом деле это не заголовок.
Остальная часть этой страницы описывает несколько важных шагов для обеспечения хорошей структуры ваших документов, доступной для пользователей вспомогательных технологий.
Методы
Заголовки
Заголовкипозволяют посетителям сайта быстро увидеть, как организована страница, но знаете ли вы, что они также могут принести такую же пользу незрячим пользователям? Правильно реализованная структура заголовков служит двум целям для этих пользователей:
- Они представляют собой схему страницы.Это позволяет пользователям понять, как структурирована страница и как разделы связаны друг с другом.
- Они предоставляют цели, поэтому пользователи могут переходить от заголовка к заголовку одним нажатием клавиши (например, буква «H» в некоторых программах чтения с экрана).
Согласно текущим веб-стандартам, предложенным Консорциумом World Wide Web, веб-страницы должны следовать иерархической структуре заголовков без пропуска уровней. То есть каждый заголовок не должен быть представлен без родительского заголовка.Таким образом, у вас не должно быть заголовка h4 без заголовка h3 или заголовка h3 без заголовка h2. Это позволяет пользователям вспомогательных технологий бегать по странице с помощью табуляции по заголовкам в логической манере, чтобы получить информацию, которую они ищут, без необходимости пролистывать весь текст страницы сверху вниз.
Когда заголовки отображаются не по порядку, это может дезориентировать человека, который не видит вашу страницу. Это как найти приложения в середине документа, а затем обнаружить, что оглавление помещено после глоссария.
Никогда не рекомендуется использовать заголовки для форматирования. Всегда лучше использовать заголовки по их семантическому, целевому назначению и вместо этого использовать CSS для форматирования текста.
Как добавлять заголовки с помощью HTML
Ниже приведены рекомендации по использованию заголовков HTML:
- Используйте
для основного заголовка страницы. Для большинства страниц будет только один - Используйте
- Используйте дополнительные уровни заголовков (от
до - Убедитесь, что заголовки образуют контур содержимого вашей страницы; не пропускайте уровни заголовков.
Как добавлять заголовки на холсте
При добавлении содержимого на страницы с помощью редактора форматированного текста в Canvas используйте переключатель «Формат» на панели инструментов, чтобы выбрать соответствующий уровень заголовка.Если текст заголовка еще не набран, сначала выберите уровень заголовка, затем введите. Если текст заголовка уже существует, просто выберите его, прежде чем использовать селектор формата для назначения уровня заголовка.
Обратите внимание, что Заголовок 1 уже используется; Canvas автоматически присваивает это заголовку страницы. Следовательно, самый высокий уровень заголовка, который вы можете выбрать в своем контенте, — Заголовок 2 .
Как добавлять заголовки в WordPress или Drupal
WordPress, Drupal и другие системы управления контентом имеют редактор форматированного текста для создания контента.В редакторе есть панель инструментов с переключателем формата, аналогичная показанной выше в Canvas. Используйте этот селектор формата, чтобы выбрать соответствующий уровень заголовка для вашего контента.
Как добавлять заголовки в Microsoft Word
В Microsoft Word добавьте заголовки, используя встроенные стили заголовков (Заголовок 1, Заголовок 2 и т. Д.), Доступные на ленте. Чтобы изменить внешний вид любого из этих стилей заголовков, щелкните правой кнопкой мыши кнопку стиля и выберите «Изменить».
Списки
При создании контента важно понимать, когда ваш контент является списком элементов.Например, веб-страницы университетов часто содержат списки ссылок, событий, сотрудников, программ на получение степени и многое другое. Если списки созданы как списки, программы чтения с экрана могут информировать своих пользователей о том, что они попали в список, и могут предоставить дополнительную информацию, например количество элементов в списке. Это чрезвычайно полезная информация для пользователей, когда они решают, читать ли дальше.
Все среды разработки документов включают функции, позволяющие добавлять маркированные или нумерованные списки, обычно с панели инструментов.
Столы
Таблицы следует использовать только для представления строк и столбцов данных, а не для организации макета страницы. При создании таблицы данных имейте в виду, что зрячие пользователи могут легко сканировать и понимать таблицу, глядя на заданную ячейку данных вместе с ее заголовками строк и столбцов и сравнивая их с другими ячейками данных. Люди, которые не могут видеть стол, не имеют доступа ко всем визуальным подсказкам, которые делают это возможным. Следовательно, они зависят от того, что автор таблицы предоставил разметку, которая явно определяет роли и отношения всех частей таблицы.Например, все заголовки столбцов должны быть идентифицированы как заголовки столбцов, а заголовки строк должны быть идентифицированы как заголовки строк.
См. Статью WebAIM «Создание доступных таблиц» для получения информации о конкретных методах HTML.
Основные роли доступных полнофункциональных интернет-приложений (ARIA)
ARIA — это спецификация W3C, которая предоставляет средства, с помощью которых веб-разработчики могут определять роли, состояния и свойства компонентов пользовательского интерфейса, чтобы эта информация была доступна вспомогательным технологиям.
Одна из самых простых в реализации функций ARIA, которая обеспечивает немедленные значительные преимущества для пользователей программ чтения с экрана, — это знаковых ролей . Каждая из восьми ролей представляет собой блок контента, который обычно встречается на веб-страницах. Они используются простым добавлением соответствующего атрибута роли в соответствующий контейнер в разметке HTML. После добавления пользователи программы чтения с экрана могут быстро перейти к этому разделу страницы. Восемь ролей:
- роль = «баннер»
- role = «навигация» (напр.г., меню)
- role = «main» (основное содержание страницы)
- role = «дополнительный» (например, боковая панель)
- role = «contentinfo» (метаданные о странице, обычно нижний колонтитул)
- role = «search»
- роль = «форма»
- role = «application» (веб-приложение с собственным интерфейсом клавиатуры)
Если роль используется на странице более одного раза, следует также использовать атрибут aria-label , чтобы различать эти две области.Например, веб-страница может иметь две области навигации: одна с aria-label = "Main Menu" , а другая с aria-label = "Audience Menu" .
Внимание: будьте осторожны, используя
role = «application» Когда используется role = "application" , ожидается, что приложение будет иметь свою собственную модель для навигации и управления всеми элементами управления с клавиатуры, а текст справки легко доступен, чтобы пользователи могли изучать нажатия клавиш. Когда вспомогательные технологии обнаруживают контент, помеченный как role = «application», они перестают отслеживать нажатия клавиш пользователей и передают все функции приложению.Это может быть проблематично, поскольку противоречит ожиданиям пользователей. Клавиши, которые обычно выполняют определенные функции при использовании своих вспомогательных технологий, внезапно перестают выполнять эти функции.
Следовательно, вы должны использовать role = "application" только в том случае, если приложение было тщательно разработано с учетом доступности, и были предприняты шаги, чтобы проинформировать пользователей о том, чего ожидать.
Формы
Большинство форм включают поля формы, сопровождаемые метками или подсказками. Чтобы выяснить, какие метки сопровождают какие поля, зрячие пользователи полагаются на визуальные подсказки, такие как относительное положение и близость.Для пользователей, которые не могут видеть форму, отношения между метками и полями должны быть явно указаны в коде. Подробнее о том, как это сделать, см. На нашей странице, посвященной созданию доступных форм.
Список литературы
Информационная архитектурадля веб-дизайна: пошаговое руководство
Время чтения: 16 минутПредставьте себе такую ситуацию: вы посещаете веб-сайт и проводите время в поисках нужной информации.Вы переходите по одной ссылке, потом по другой, и снова, и снова … Но вы ничего не видите — ничего полезного не найдете. Независимо от того, являетесь ли вы владельцем продукта или дизайнером, вы не хотите, чтобы ваш веб-сайт превратился в лабиринт, в котором нет ничего, кроме разочаровывающих тупиков.
Информационная архитектура помогает избежать этого. Он справляется с хаосом, создавая четкую структуру для веб-сайта, приложения или программы. В этой статье мы объясним, как создать превосходную информационную архитектуру.
Что такое информационная архитектура?
Когда вы приедете в новое место, вам нужно что-то направить.Если вы проводите выходные в незнакомом городе, вам нужно свериться с картой. Затем вы используете уличные знаки и адреса на зданиях, чтобы добраться до места назначения. То же самое и с любым незнакомым местом: вы не хотите терять время и теряться, поэтому вам нужен совет.
Информационная архитектура (IA) — это наука о структурировании контента применительно к новостным веб-сайтам или блогам, интернет-магазинам, приложениям для бронирования, загружаемому программному обеспечению и т. Д. Целью информационной архитектуры является классификация контента в ясной и понятной форме. способ и упорядочить его в соответствии с отношениями между частями контента, позволяя пользователям находить то, что им нужно, с меньшими усилиями.Не применяется только при создании продукта с нуля, IA используется при редизайне.
Информационная архитектура — это часть дизайна взаимодействия, которая учитывает контент, контекст и пользователей. Это означает, что при структурировании информации о продукте необходимо учитывать потребности пользователей, бизнес-цели и различные типы контента.
Основные компоненты информационной архитектуры, источник: Люсия Ванг
Обычно дизайн информационной архитектуры находится в ведении дизайнеров UX и UI или информационного архитектора.Чтобы избежать путаницы, давайте кратко рассмотрим различия между этими похожими терминами.
Информационная архитектура, UX и UI
IA, UX и UI тесно связаны и подпадают под действие концепции дизайна продукта, но это не одно и то же. Проверьте определения.
UX или взаимодействие с пользователем — это то, что чувствуют пользователи, когда они взаимодействуют с продуктом. Итак, цель UX-дизайна — сделать продукт практичным, полезным, привлекательным и т. Д. — другими словами, создать положительный опыт от его использования.
Пользовательский интерфейс или пользовательский интерфейс является важной частью UX, поскольку он имеет дело с визуальным аспектом продукта и интерактивностью, стоящей за ним. Итак, дизайн пользовательского интерфейса напрямую влияет на UX, поскольку привлекательная графика и простое, интуитивно понятное взаимодействие являются неотъемлемыми частями плавного взаимодействия с пользователем.
IA или информационная архитектура относится к организации и маркировке контента, чтобы сделать продукт удобным и понятным, а также улучшить взаимодействие с пользователем. Так что в некотором смысле дизайн IA — это основа UX.
Для наглядности приведу аналогию. Вы можете сравнить IA с каркасом продукта, который поддерживает и удерживает все части в нужном месте. Затем пользовательский интерфейс — это внешний вид, который видят другие люди при взаимодействии с продуктом. А UX — это эмоция, которая возникает в результате такого взаимодействия.
Вот отличная визуализация взаимосвязи этих терминов.
Как связаны IA, UX и UI, кредит изображения: Scorch
Питер Морвилл, соавтор Информационная архитектура для Всемирной паутины , объясняет роль информационного архитектора как человека, который объединяет пользователей и контент, разрабатывая поиск и навигацию, воплощая абстрактные идеи в прототипы, единицы , и дисциплины, чтобы превратить концепции в нечто понятное.Информационный архитектор, работающий вместе с UX-дизайнером, может сосредоточиться исключительно на проектировании информационной архитектуры, в то время как UX-дизайнер уделяет больше времени исследованиям. В этом случае архитектор создает ряд результатов, которые мы опишем в разделе, посвященном этапам разработки IA.
Независимо от названия, человек, который работает над информационной архитектурой, должен начинать с правил, которые помогают достичь цели IA. В следующей части статьи мы более подробно рассмотрим деятельность по проектированию ИА и ее результаты.Чтобы создать надежную информационную архитектуру, вы должны начать с тщательного исследования, поэтому все начинается с изучения потребностей и поведения ваших пользователей.
Ключевые этапы развития информационной архитектуры
1. Изучение клиентов
Цель этого этапа — узнать о потребностях пользователя. Вы должны работать с профилем клиента и результатами собеседований с клиентами и заинтересованными сторонами. Данные, полученные на этом этапе, позволят вам создать профиль пользователя, составить список бизнес-требований и получить представление о том, чего хочет пользователь.Поскольку эти задачи принадлежат UX-дизайнеру или бизнес-аналитику, вам нужны результаты их деятельности.
В конце этого этапа у вас будет профиль и последовательность действий пользователя, которые иллюстрируют, как пользователь думает и взаимодействует с продуктом. Когда у вас есть вся необходимая информация о продукте и людях, которые его используют / будут использовать, вы можете переходить к следующему шагу.
2. Просмотрите и обновите содержимое
Как только вы узнаете, чего хочет пользователь, вы можете обновить содержимое существующего веб-сайта и внести его в список.Основными действиями, которые необходимо выполнить на этом этапе, являются инвентаризация контента и аудит контента . Рассмотрим каждую из них поближе.
Инвентаризация
Цель этого упражнения — создать список информационных элементов на всех страницах веб-сайта и классифицировать их по темам и подтемам. Сюда входят следующие позиции:
- Заголовки и субпозиции
- Тексты
- Медиа-файлы (изображения, видео, аудио)
- Документы (doc, pdf, ppt)
- URL-ссылок страниц
Эти элементы перечислены в шаблоне контента с их характеристиками.
Шаблон инвентаризации контента, источник: Eckford
Контент-аудит
Итак, у вас есть список содержимого. Теперь оцените его точность, стиль изложения и полезность. Затем удалите наименее важные элементы, обновите устаревшие фрагменты контента и перегруппируйте их для следующих шагов. Это действие применимо как к новым продуктам, так и к редизайну приложений или веб-сайтов.
Следующий шаг включает группировку контента по разным категориям.Здесь вам понадобится помощь потенциальных пользователей.
3. Применить сортировку карточек для классификации содержимого
Все типы контента должны быть классифицированы и иметь собственные имена, которые не запутают пользователя. Для этого вам нужна таксономия. Таксономия — другое слово для обозначения классификации. В случае с IA это попытка сгруппировать различные неструктурированные части информации и дать им описания.
Таксономизация на сайте Airbnb, источник: Stanford K.Kekauoha
Самым популярным и самым важным методом, позволяющим систематизировать контент, является сортировка карточек.
Сортировка карт
Как только у вас будет контент, оформляйте его. Смысл упражнения в том, чтобы напрямую увидеть, как пользователи воспринимают элементы контента продукта. Сортировка карточек обычно проводится в небольших группах по 15-20 участников, где они должны описать и отсортировать 30-60 карточек с информацией по разным классам. Карточки содержат темы, которые необходимо классифицировать, или фрагменты контента, которые необходимо описать.
Как работает сортировка карточек, источник: Дизайн взаимодействия
Существует три типа сортировки карт:
Открыть — для бесплатной маркировки. Участники классифицируют темы, как им нравится, и в том порядке, который им понятен. Такой подход позволяет понять, как думают пользователи с точки зрения классификации. Открытый тип используется для разработки новых продуктов.
Закрыт — с заранее разработанными категориями.Этот метод сортировки карточек обычно применяется при редизайне. Участникам даются предопределенные категории из списка инвентаризации контента, и они сортируют контент в соответствии с ними.
Hybrid — объединяет элементы обоих типов или начинается с открытого типа, переходя к закрытому типу, чтобы следовать логике пользователя.
Вы можете проводить сортировку карточек в группах, как личное собеседование или удаленно с помощью инструментов IA, таких как UserZoom или Optimal Sort .
Карты могут быть цифровыми или физическими, т.е.е. написано на бумажках. При создании карточек используйте результаты инвентаризации контента. Отдельные темы должны быть на отдельных учетных карточках. На них должны быть числа, а в некоторых должны быть пробелы, чтобы участники могли создавать свои собственные имена для категорий. В результате вы увидите примерную структуру продукта и приступите к созданию первых прототипов. Но сначала категории должны быть помечены и определены в системе навигации.
4. Создайте иерархию веб-сайтов для удобной навигации
Каждому веб-сайту или приложению нужна надежная система навигации, которая помогает пользователям находить то, что им нужно.Как только у вас появятся результаты деятельности по сортировке карточек, вы поймете, как воплотить и классифицировать контент в реальности. Этот шаг включает в себя дизайн навигации, маркировку и отображение сайта. Давайте определим их по очереди.
Навигация
При работе с навигацией помните, что независимо от того, с каких страниц приходят посетители, они должны иметь возможность легко находить то, что ищут. Термины IA и навигация иногда используются как взаимозаменяемые.Однако это не одно и то же, поскольку навигация — это всего лишь часть IA. При разработке своего веб-сайта или приложения важно не сосредотачиваться только на навигации, поскольку в конечном итоге вы рискуете обнаружить, что она не вмещает весь объем содержания и функций вашего сайта.
Система навигации состоит из множества элементов — кнопок, меню и таблиц содержания. Существует четыре основных типа навигации:
Иерархический — показывает иерархию информации от основных элементов до их подкатегорий.Примером могут служить раскрывающиеся меню для крупных веб-сайтов.
Выпадающее меню на главной странице веб-сайта Walmart, Источник: Walmart
Глобальный или общесайтовый — присутствует на всех страницах, эта навигация позволяет пользователям переходить на главную страницу из любого места, например, из левого или правого, по центру вверху, липких меню, нижних колонтитулов или гамбургерное меню.
Левостороннее меню в Википедии, источник: Википедия
Локальный — показывает навигацию по определенной области: странице или части сайта и ее содержимому.Он может быть представлен в виде списков.
Локальная навигация на сайте Udemy, источник: Udemy
Контекстный — относится к определенному контенту, например документу, странице, видео-аудио объекту или связанным продуктам. Например, в нашем блоге мы размещаем ссылки на наши предыдущие материалы вместо того, чтобы подробно объяснять все, чтобы вы могли их изучить только в том случае, если вам это интересно.
Эти типы могут дополнять друг друга, но главный принцип хорошей навигации — избегать перегрузки направляющими элементами.
Несколько компонентов навигации на веб-сайте SBA , источник: NN Group
Иногда навигация может быть представлена в виде интерактивного гида, тура или учебника. Он может перемещать пользователя через многоэтапный процесс или сложный веб-сайт. Вы можете выбрать лучший вариант для местоположения и типа меню, проведя A / B и многовариантное тестирование для оптимизации конверсии.
Кроме того, если вы разрабатываете IA для сложного приложения или веб-сайта с большим количеством информации, подумайте о дополнении навигации поисковой системой , которая не даст пользователям потеряться.Это обычная практика для электронной коммерции, онлайн-баз данных, словарей и других информационных сайтов. Вы можете внедрить поисковую систему и систему фильтров, чтобы помочь пользователям быстро найти то, что им нужно.
Поиск слова в словаре, источник: Merriam-Webster
Маркировка
Правильный ярлык дает пользователям правильное представление о категории, с которой они имеют дело. Во время этой процедуры назовите все части IA заголовками и подзаголовками.Назначение ярлыков — привлечь внимание пользователя, давая правильное представление о том, чего ожидать от нажатия на ссылку. Примеры — лучшее описание, поэтому проиллюстрируйте свои ярлыки.
Маркировка веб-сайтов Google Travel с именами и значками, источник: Google Travel
После того, как вы наметите навигацию и маркировку, пора определиться с шаблоном проектирования иерархии.
Шаблоны проектирования иерархии
Шаблон проектирования — это способ структурировать контент.Это позволяет вам выбрать направление в самом начале работ по созданию ИА или редизайну сайта. Существует несколько шаблонов проектирования IA, в зависимости от типа, количества и взаимосвязи содержимого вашего веб-сайта.
Одностраничная модель — та, которая служит единственной цели, например, загрузка приложения или предоставление контактной информации.
Плоская структура — структура с линейной иерархией, где все страницы одинаково важны. Этот шаблон подходит для веб-сайтов, похожих на брошюры.
Плоская конструкция
Шаблон индексных страниц — состоит из домашней страницы и не менее важных подстраниц. Этот тип — один из наиболее распространенных вариантов для веб-сайтов, поскольку он простой, знакомый и достаточно глубокий для большинства случаев использования.
Шаблон индексных страниц
Шаблон строгой иерархии — аналогичен шаблону индексных страниц, но более разветвлен: каждая подстраница имеет одну или несколько подстраниц.Шаблон строгой иерархии выбирается веб-сайтами, имеющими большое количество категорий, например блогами, сайтами электронной коммерции или СМИ.
Шаблон строгой иерархии
Шаблон сосуществующих иерархий — объединяет несколько типов иерархий в случае, если информация из одной подстраницы перекрывает содержимое другой.
Шаблон сосуществующей иерархии
Как только вы определились с шаблоном проектирования, вы можете применить его вместе с результатами сортировки карточек при сопоставлении сайтов.Однако созданию карты сайта часто предшествует интеллектуальная карта.
Интеллект-карта
Mind mapping — это метод, основанный на взаимосвязях между разными страницами цифрового продукта с подробным описанием функциональности. В качестве инструмента интеллект-карта очень полезна для обучения, позволяя кому-то понять структуру содержания в логической последовательности и развить ассоциации. Примените его к приложению или веб-сайту, чтобы визуально представить сущности продукта и следовать логической структуре контента.
Интеллектуальная карта для веб-сайта информационных систем Cornerstone и приложения для iOS
Теперь, имея интеллект-карту, вы можете создать карту сайта.
Карта сайта
Карта сайта — это способ иллюстрировать иерархию контента и отображать навигацию. Слово карта сайта говорит само за себя. Это карта содержания и категорий веб-сайта.
Карта сайта портфолио, s ource: Kellyn Loehr on Dribble
На карте сайта вы визуализируете всю иерархию контента.Вы можете сделать это на бумаге или с помощью различных инструментов, таких как WriteMaps или MindNode.
Карты сайта для проектирования IA обычно создаются в форме диаграмм и называются диаграммами информационной архитектуры . Они также могут быть представлены в форматах XML или HTML, чтобы помочь поисковым системам понять структуру вашего веб-сайта и найти соответствующую информацию. XML почти не читается пользователями (посмотрите этот пример карты сайта Victorious XML), но карты сайта в формате HTML выглядят как обычные веб-страницы и могут быть прочитаны как людьми, так и роботами поисковых систем.Вот пример карты сайта Apple в формате HTML.
Покажите карту сайта заинтересованным сторонам и отправьте ее разработчикам, чтобы они поняли, что делать дальше: есть ли какие-либо важные изменения, которые необходимо внести до того, как продукт будет запущен в производство? Но до производства остается еще один этап — прототипирование.
5. Создайте прототип пользовательского интерфейса для будущей разработки
Хотя карта сайта является первым прототипом в разработке информационной архитектуры, вам все равно придется создавать расширенные прототипы с помощью каркасов и моделирования данных.
Каркас
В то время как карта сайта — это схема иерархии контента, каркас воплощает окончательный вид. Каркас — это схематическое представление веб-сайта или приложения, которое отображает навигацию и интерфейс веб-сайта. Каркас IA показывает все страницы и экраны продукта с заголовками, тегами, ярлыками и серыми полями, в которые будет помещен контент. Это также первый набросок пользовательского интерфейса цифрового продукта.
Этот результат представляет собой мост между информационным архитектором и дизайнером UX / UI.Используя каркас, вы можете провести пользовательское тестирование, чтобы понять, служит ли IA своей цели. Эти результаты тестирования позволят вам применить изменения до того, как разработчики и дизайнеры пользовательского интерфейса начнут работать над продуктом.
Каркас веб-приложения Back to my body, s ource: Alyoop
Каркасы создаются на бумаге или с помощью специального программного обеспечения, такого как Justinmind или Visio, для создания цифровых каркасов, карт сайта или прототипов с высокой точностью. Каркасы тестируются пользователями, чтобы определить, является ли структура ясной и лаконичной.
Моделирование данных
Последний шаг перед разработкой — моделирование данных: вы можете реализовать структуру содержимого в системах моделирования данных. На этом этапе вы сообщаете прототипы заинтересованным сторонам и разработчикам для работы над продуктом.
Обычно это делается с помощью каркасов или прямо через CMS (системы управления контентом), которые являются вспомогательными системами для публикации контента, такими как Squarespace, WordPress и Wix. Разместите контент через CMS, а затем используйте его в качестве платформы для разработки веб-сайтов.
6. Тестируйте и улучшайте
Тестирование может проводиться на разных этапах процесса проектирования, чтобы направлять дизайнеров и совершенствовать внутреннюю архитектуру. Они часто являются частью фазы исследования, особенно если вы ищете способы изменить дизайн существующего приложения или веб-сайта.
Однако совершенно необходимо протестировать вашу информационную архитектуру, как только прототип будет готов и до того, как он попадет в команду разработчиков. Эта практика может помочь вам избежать дорогостоящих ошибок, таких как необходимость переделывать ваш продукт.Здесь применяются такие методы, как юзабилити-тестирование и тестирование по первому клику. Вы можете протестировать как первоначальные прототипы (часто бумажные черновики), так и интерактивные прототипы, чтобы обнаружить возможные проблемы с навигацией или макетом.
Юзабилити-тестирование
Юзабилити-тестирование позволяет убедиться, что разработанная структура работает для ваших пользователей. Во время юзабилити-тестирования участники должны взаимодействовать с вашим продуктом обычным образом, как если бы они это делали в реальной жизни. Например, вы можете попросить их поискать определенную информацию (например,g., контактные данные или платежные реквизиты, определенный товар для продажи и т. д.) или выполнить конкретную задачу (например, зарегистрировать новую учетную запись, совершить покупку и т. д.). Очевидно, они не могут найти ответы, поскольку контент еще не готов, но они все равно могут указать свой образ действий при взаимодействии с вашим будущим продуктом.
Наблюдая за их действиями и собирая отзывы, вы можете узнать, какие части работают правильно, а какие нет, а что нужно исправить. Основная цель здесь — проверить, могут ли пользователи легко получить то, что им нужно, из вашего приложения или веб-сайта.
Тестирование первого клика
Тестирование первого клика также помогает измерить удобство использования, определяя, является ли первый клик, сделанный посетителем в интерфейсе приложения или веб-сайта, простым и интуитивно понятным. Он показывает, как пользователи перемещаются по вашему сайту и насколько легко им делать то, что они хотят.
Во время такого тестирования вы готовите несколько типичных сценариев (как и при тестировании удобства использования) и определяете оптимальные способы их прохождения. Затем раздайте задачи своим пользователям и отслеживайте, где они нажимают и сколько времени им требуется, чтобы найти правильное решение.Иногда первый щелчок может быть правильным, но поиск нужной кнопки или ссылки занимает слишком много времени. В других случаях первый щелчок ошибочен, и для перехода на нужную страницу требуются дополнительные шаги (если они вообще туда попадают).
Тестирование по первому щелчку может выявить проблемы с навигацией и макетом на этапе прототипирования или на работающем веб-сайте / приложении. При проведении тестирования не забывайте собирать качественные данные в дополнение к количественной информации о кликах. Объяснения пользователей на , почему они сделали то, что они сделали, помогут вам лучше понять своих клиентов и улучшить свой продукт.
Восемь принципов информационной архитектуры
Независимо от того, хотите ли вы улучшить пользовательский интерфейс веб-сайта или создать совершенно новое приложение, вы должны принять во внимание восемь принципов.
Восемь принципов информационной архитектуры, источник: CareerFoundry
Эти восемь принципов были определены Дэном Брауном, соучредителем дизайнерской компании EightShapes. Информационный архитектор должен придерживаться их при создании продукта:
- Принцип объектов — контент — это живое существо со своим жизненным циклом, поведением и атрибутами.
- Принцип вариантов выбора — страницы продукта должны предлагать пользователям ряд значимых вариантов выбора.
- Принцип раскрытия информации — пользователей нельзя перегружать информацией; показывать только ту информацию, которая поможет им понять, какую информацию они найдут, копая глубже.
- Принцип экземпляров — лучший способ описать категории контента — показать примеры контента.
- Принцип входных дверей — предположим, что по крайней мере половина посетителей веб-сайта будет проходить через какую-то страницу, отличную от главной.
- Принцип множественной классификации — предложить пользователям несколько различных схем классификации для просмотра содержимого сайта.
- Принцип ориентированной навигации — не смешивайте разные категории в своей навигационной схеме.
- Принцип роста — предположите, что контент, который у вас есть сегодня, составляет небольшую часть контента, который у вас будет завтра.
Применяя эти принципы, вы, вероятно, эффективно структурируете существующий контент и оставите пространство для роста.
Примеры информационной архитектуры
Как вы уже видели, почти на каждом этапе есть свои результаты. Но наиболее важным продуктом, объединяющим результаты тяжелой работы информационного архитектора, является карта сайта. Теперь давайте посмотрим на некоторые реальные карты сайта, чтобы увидеть, как они структурируют свое содержание.
Глобальная сеть семян
Глобальная сеть семян — это инициатива, которая поддерживает разнообразие и защищает систему общественного питания, поощряя фермеров и садоводов делиться семенами разных растений.Информационная архитектура сайта имеет простую систему навигации и позволяет новым посетителям зарегистрироваться в два этапа и найти доступные типы семян прямо на главной странице. Также на главной странице представлены последние новости. Все это показывает посетителям преимущества инициативы и помогает им принять решение.
Global Seed Network Sitemap, s ource: 1 st Way
Spotify
Оригинальный дизайн Spotify был примером плохой информационной архитектуры.На веб-сайте Spotify использовался шаблон сосуществующей иерархии с повторением и частичным повторением некоторых разделов. Это сделало информационную архитектуру запутанной, поскольку пользователи изо всех сил пытались найти то, что им нужно, и терялись в избыточных пунктах меню.
Карта сайта Spotify, s ource: Renee Lin on Medium и др.
Рене Лин, UX-дизайнер, нашла способ улучшить его, упростив и удалив некоторые разделы. Это пример того, как можно изменить дизайн существующего веб-сайта, чтобы пользователям было легче перемещаться по нему и взаимодействовать с ним.
Spotify IA пересмотреноТипичная карта сайта о путешествиях
Вот как может выглядеть веб-сайт туристической компании или онлайн-туристического агентства. Помимо таких важных функций, как бронирование поездок или управление личным счетом, он также может содержать различные параметры сортировки, советы путешественникам и другую несущественную, но полезную информацию. В то же время предлагаемая структура проста и интуитивно понятна для посетителей.
Образец карты сайта туристического веб-сайта, источник: Visual Paradigm
Мы уже упоминали некоторые популярные инструменты, которые используются для создания IA.Здесь мы кратко перечислим, что может помочь на разных этапах.
Инструменты для онлайн-сортировки карт включают
Для создания карты сайта в Интернете , вы можете использовать такие платформы как
Прототипы и каркасы могут быть созданы с помощью
Диаграммы и блок-схемы разработаны и распространяются через такие платформы, как
Испытания и исследования могут быть проведены с использованием
Системы управления контентом (CMS) , которые могут пригодиться, включают
Последние тенденции IA
Одна из основных тенденций в дизайне UX / UI — нулевой UI.Если вы когда-либо использовали Google Assistant или Alexa, вы знаете, на что это похоже: пользователь находит необходимую информацию, даже не касаясь экрана, просто сказав пару слов или просто жестом. Это то, что чаще всего применяют проекты виртуальной реальности и интеллектуальные устройства, позволяя пользователям взаимодействовать с безэкранным интерфейсом. В конце концов, технология нулевого пользовательского интерфейса позволит людям общаться с различными устройствами, используя не только движения или голос, но также взгляды и даже мысли.
Как структурировать информацию о компании Wiki
Каждая компания, большая или маленькая, имеет ряд политик, руководств, процедур, рабочих процессов и информации, которые необходимо сообщить, чтобы гарантировать, что все находятся на одной странице и что работа выполняется определенным образом и до определенный стандарт.Некоторые компании строго придерживаются этого правила, в то время как другие управляются свободно и свободно, но все они имеют по крайней мере фундаментальное понимание того, что следует и что нельзя делать.
Компании используют разные способы передачи важной служебной информации. Некоторые будут использовать импровизированный подход «как есть», предоставив сотрудникам возможность напрямую запрашивать любую необходимую информацию и предоставлять ее на лету. Другие будут засыпать своих сотрудников нескончаемым потоком электронных писем (или — черт возьми! — бумажных документов) или ненужных встреч даже для мельчайших универсальных деталей.
Компании используют разные способы передачи важной информации, связанной с работой.Как насчет того, чтобы уладить все на простой корпоративной вики?
Умные компании, если вы спросите нас, внедрите a company wiki — общий информационный центр, который собирает всю необходимую информацию и знания, связанные с работой. Его преимущества многочисленны как для крупного, так и для малого бизнеса. Исследования, проведенные некоторое время назад, показали, что корпоративные вики-страницы дают три основных преимущества: повышение репутации, простота и прогресс компании.
Другими словами, хорошо структурированная вики-страница компании сэкономит время, создаст организованный информационный поток, позволит оперативно добавлять или обновлять информацию и предоставит всем сотрудникам необходимые ноу-хау для всех обычных рабочих ситуаций. .
Самым важным шагом в создании корпоративной вики-страницы является определение структуры, обеспечивающей точность, актуальность и легкость поиска информации. Вот несколько советов, которые, как мы надеемся, помогут вам начать работу в правильном направлении.
ЦелиВики-страницы компании могут содержать широкий спектр информации, от общей информации о компании и политик поведения до конкретных рабочих процессов и баз знаний и т. Д. Прежде чем приступить к разработке вики, хорошенько подумайте о том, чего вы хотите с ее помощью достичь. Хороший способ сделать это — поставить себя на место нового сотрудника на его или ее новой работе и подумать над любой информацией, которая может им понадобиться, чтобы быстро стать продуктивным членом команды.
Прежде чем приступить к разработке вики, обязательно определите, чего вы хотите достичь с ее помощью. Краткий список типов информации, наиболее часто встречающейся на вики-страницах компании: — Общие правила и рекомендации,
— основные рабочие процедуры (настройка электронной почты, средства связи и т. д.),
— организационная структура,
— основная информация о сотрудниках,
— производственный трубопровод,
— необходимое программное обеспечение,
— база знаний,
— новости компании
(Вы можете расширить этот список, включив в него любую информацию, относящуюся к вашей компании и ее потребностям)
ОриентацияВики может содержать самую полезную информацию в мире и по-прежнему не выполнять своего предназначения, если пользователь не знает, где искать.Поэтому очень важно систематизировать разнообразную информацию на вики-странице вашей компании. В идеале вики должна быть логичной, удобной и простой в навигации. Начните с небольшого количества общих категорий, которые охватывают всю информацию, находящуюся в вики (подумайте: информация о компании, процедуры и инструкции, новости, проекты, база знаний и т. Д.), А затем сегментируйте ее дальше по каждой отдельной категории. Подумайте, как пользователь будет искать конкретную информацию, и убедитесь, что вы проверяете свои организационные способности на других — их отзывы покажут вам, на правильном ли вы пути или нет.
По возможности постарайтесь дать своим сотрудникам четкие указанияо том, как что-то делать. Простота
Позволить каждому добавить к растущей базе знаний — это здорово в теории, но не всем одинаково удобно давать свои два цента. Люди часто избегают участия из-за своих сомнений и неуверенности в предпочтительной форме и структуре и даже в содержании того, что они хотят внести. Способ решить эту проблему и упростить для всех участие — это стандартизировать вашу вики и создать шаблоны для представления любой информации.Конечно, это применимо не во всех случаях, но, по возможности, постарайтесь дать своим сотрудникам четкие инструкции о том, как что-то делать.
ИерархияОдна из определяющих характеристик вики — это открытость для всех . Его может редактировать кто угодно, и каждый может внести свой вклад в повышение общего уровня знаний и информации. Это здорово, потому что позволяет сотрудникам делиться любыми знаниями, полезными для других, и быстро и удобно обновлять любую устаревшую и неполную информацию.С другой стороны, попадание в чужие руки может привести к неверной информации. Вы можете решить эту проблему, поддерживая определенный уровень модерации.
Когда все находятся на одной волне, руководители команд становятся на шаг ближе к достижению своих целей.BlogIn встроенная вики позволяет администратору контролировать, кто может добавлять контент, путем присвоения различных ролей пользователям (это может быть другой администратор , писатель, комментатор, или считыватель ).